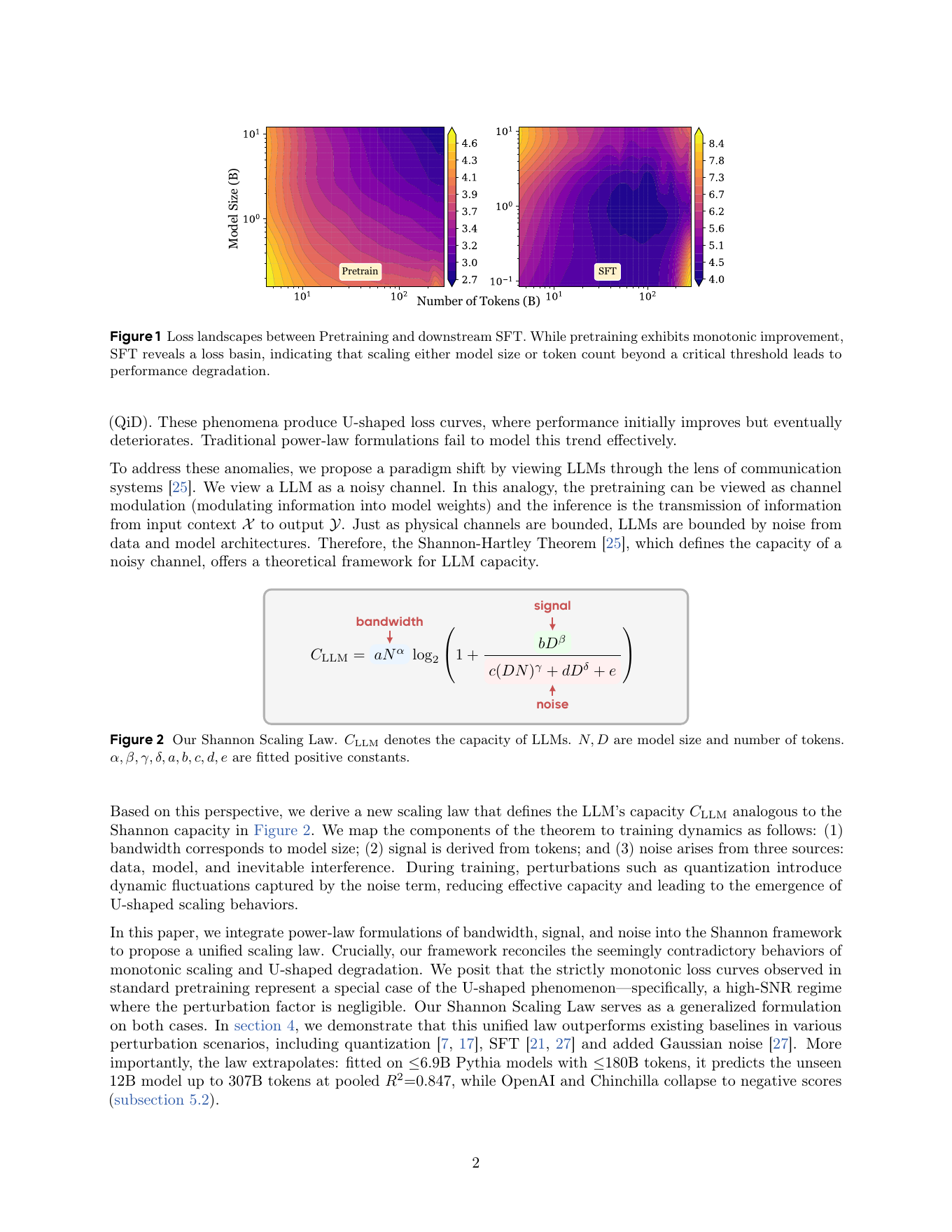
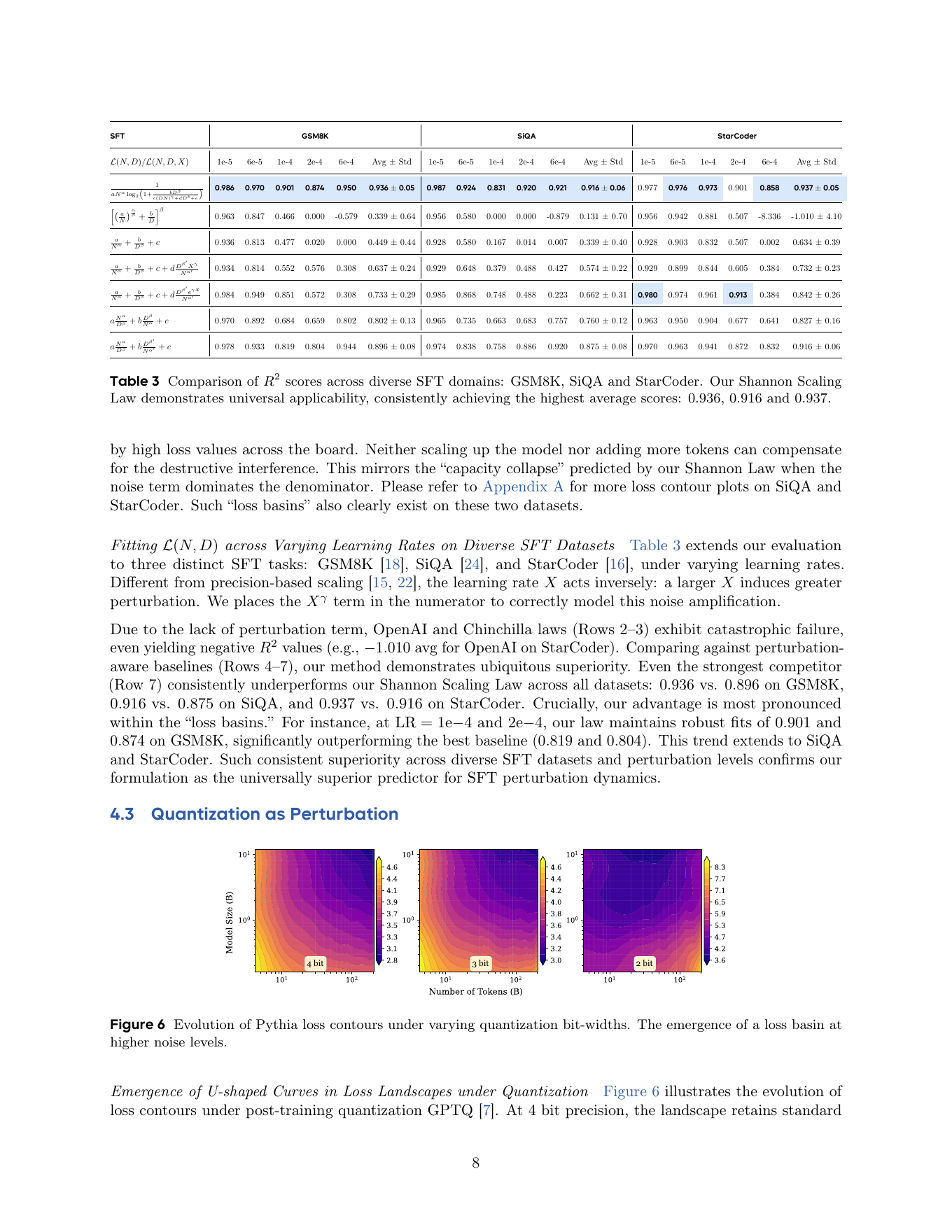
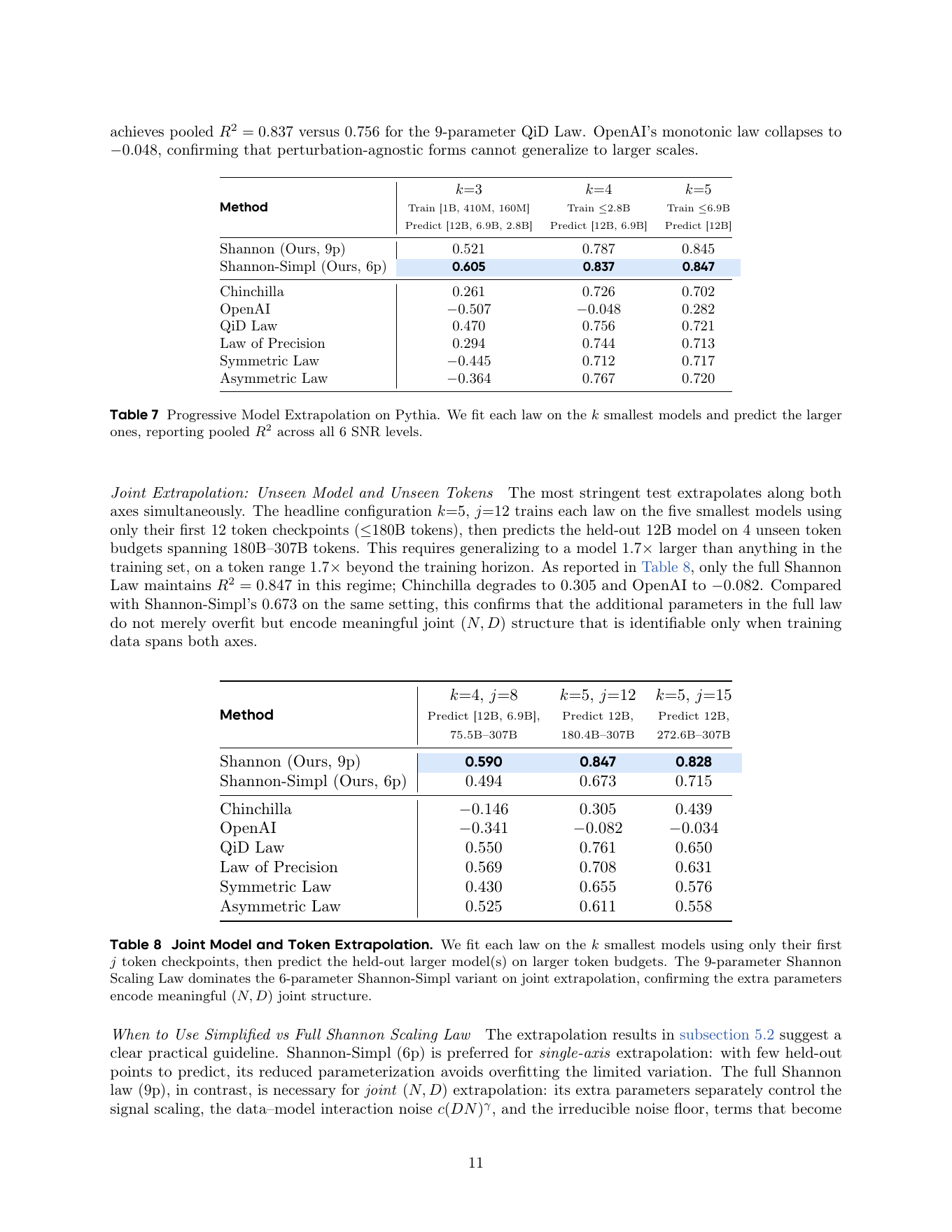
我认为这里最有价值的不是 Shannon 这个名字,而是 denominator 里的三个噪声项。它提醒我们:LLM scaling 的关键矛盾正在从稀缺 compute 逐渐转向稀缺高密度信号。早期 scaling 里,新增 token 大多提供新信息;到了更大规模,新增 token 更可能包含重复、矛盾、低质格式、错解、污染 benchmark 的轨迹、不可学习的长尾和优化扰动。
这也解释了为什么近年的训练工程越来越强调数据过滤、合成数据 verifier、curriculum、domain mixture、post-training 数据隔离和 evaluation hygiene。它们不是边缘清洁工作,而是在推迟 \(\delta\gt\beta\) 导致的反转点,或者直接改变有效 \(\delta\)。
所以,rosinality 的评论可以理解为一个很好的“极限提醒”:如果我们只会把 token 当作 signal,那么 scaling law 会过于乐观;如果我们开始把 token 同时看作 signal carrier 和 noise carrier,就会更自然地解释为什么同样的 compute,在不同数据工程和扰动条件下会得到完全不同的 scaling shape。
