核心判断
这篇报告的主语不是一个 checkpoint,而是一套“把失败模式变成下一轮控制信号”的工程系统。微软把模型研发拆成可测量、可复现、可反馈的爬坡过程:数据源如何筛、架构改动如何过 scaling ladder、MoE 路由如何不失衡、RL 何时 collapse、agentic 环境如何防作弊、安全目标如何不被加权抵消、集群健康如何变成调度状态。
报告证据地图
这份报告的结构很清楚:前半部分说明如何从 scratch 得到一个强 base model,中间说明如何用长程 RL climb 产生 reasoning / agentic / helpful-safety 能力,后半部分说明怎么评测、安全红队和运行集群。
主文 1-2 章:Base Model
介绍 MAI-Base-1 的 MoE 架构、scaling ladder、NLL evaluation、数据治理、30T 预训练、3.55T 中训练、YOLO 训练系统。
主文 3 章:RL Climb
介绍 GRPO-style objective、adaptive entropy、outer ratio clip、self-distillation、STEM / agentic / helpfulness-safety 三类专家爬坡和最终合并。
主文 4-7 章:验证与运行
覆盖 benchmark、人类 side-by-side、安全评测、红队、8K GB200 集群、goodput、MAIA-200 部署和后续方向。

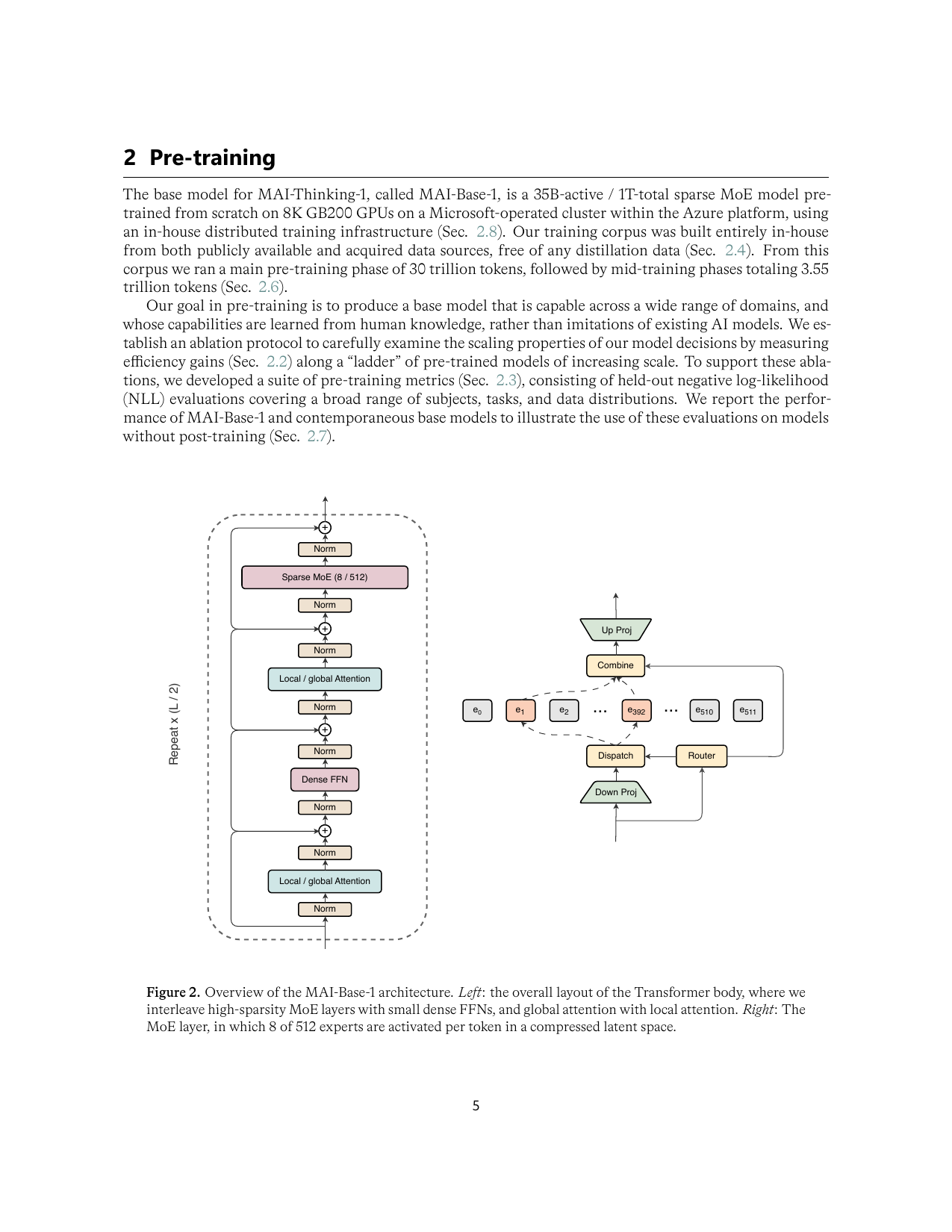
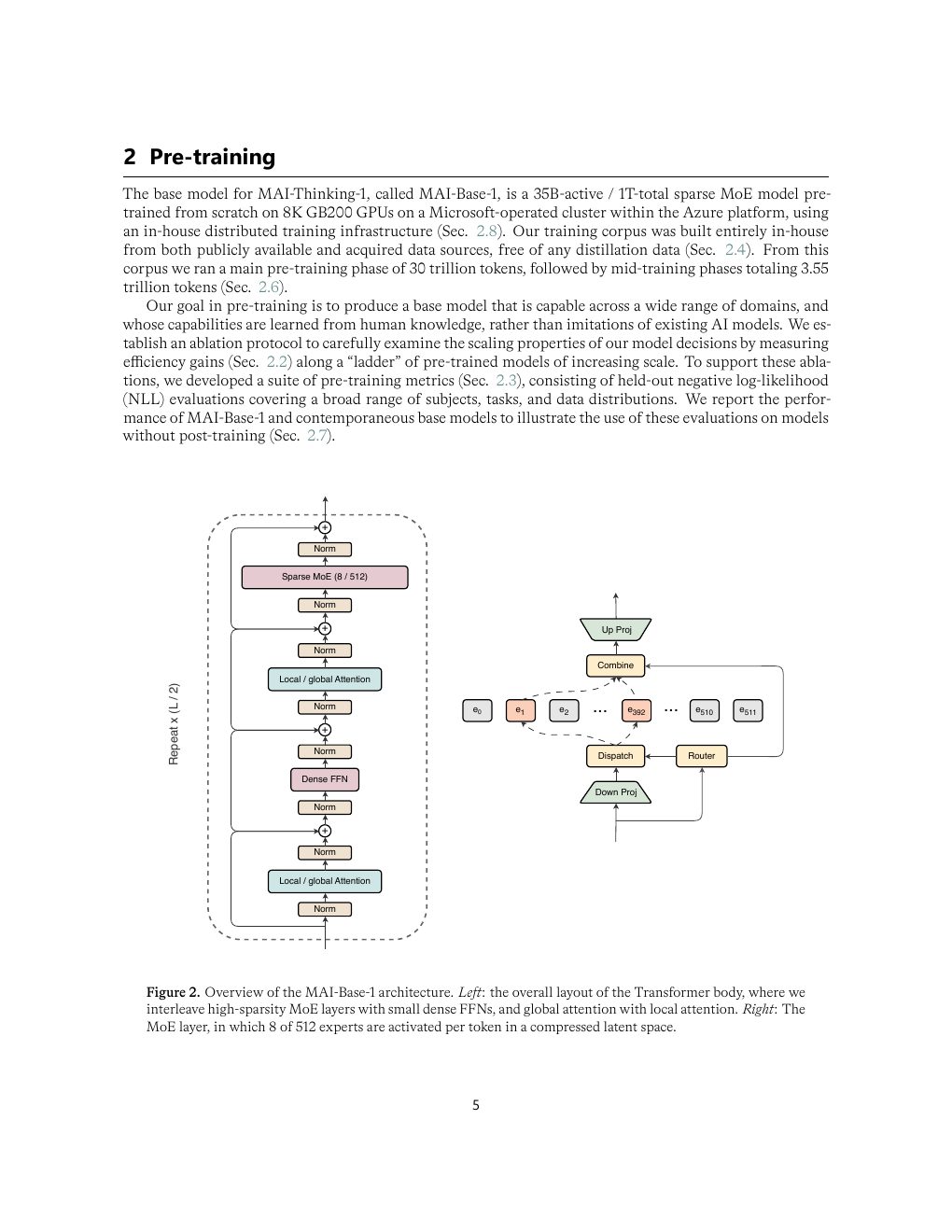
术语先对齐
Hill-climbing machine
这里指一套持续局部改进系统:每轮发现可测量提升、验证提升是否跨尺度稳定、把改动放大到大训练,再把失败模式反馈进下一轮 pipeline。
Active / total parameters
MoE 模型每个 token 只激活部分专家。active parameters 是每次 token 实际计算经过的参数量;total parameters 是所有专家和共享层的总容量。
Efficiency Gain
EG 表示候选方案达到某个 loss 时,baseline 需要多大训练成本才能追上。EGTime 则把实际 wall-clock 训练时间也纳入比较。
NLL evaluation
Negative log-likelihood 是 teacher-forcing 下的下一 token 预测损失。微软用它作为预训练日常仪表盘,因为它便宜、稳定、少受生成格式干扰。
Self-distillation
本文里不是从第三方 teacher 蒸馏,而是把自身 RL climb 中产生的高质量 reasoning traces 固化成 SFT 数据,用于恢复、迁移和重启下一段 RL。
Goodput
Goodput 指理想训练时长与实际 wall-clock 时长的比值,衡量 GPU 小时中真正转化为训练进展的比例,而不只是 MFU 或峰值 FLOPs。
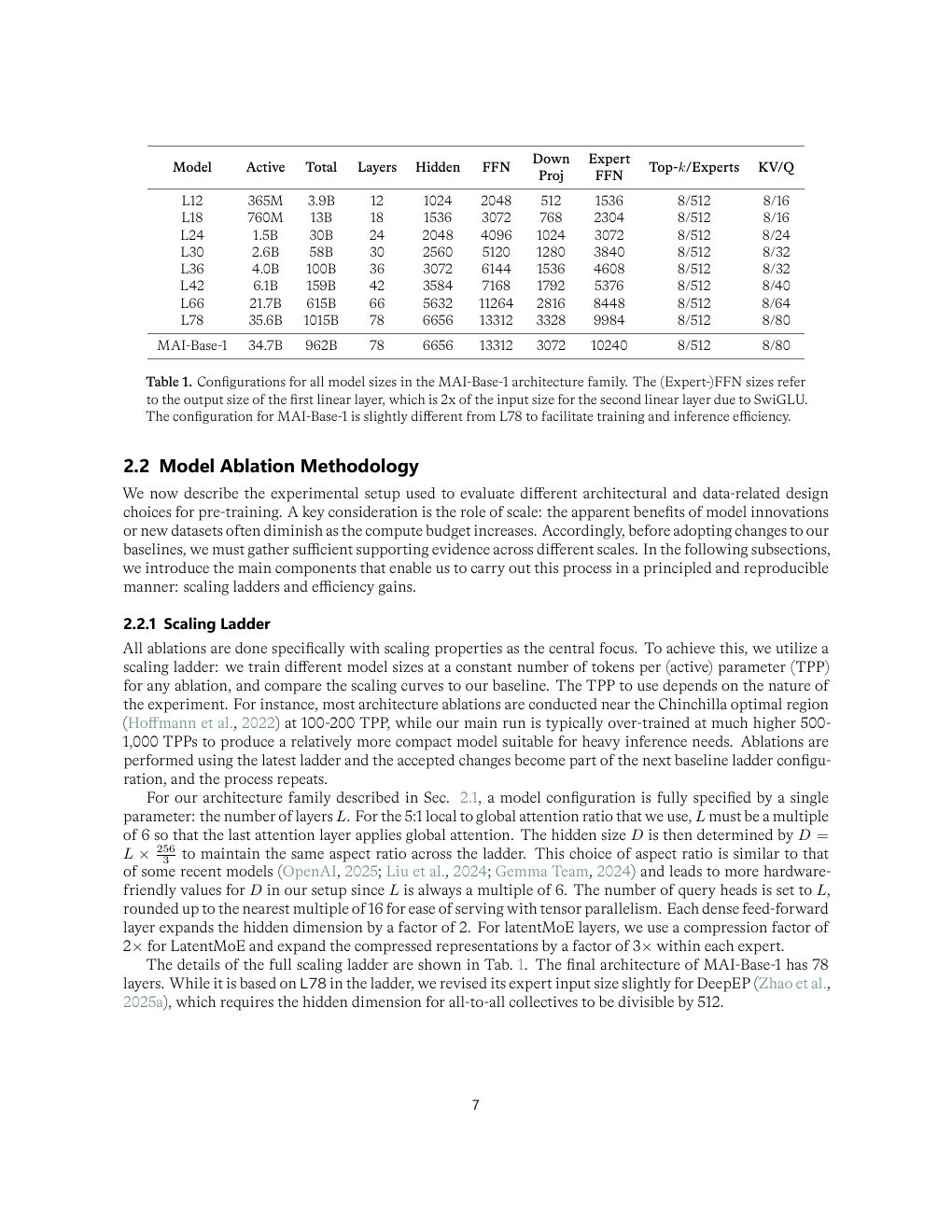
架构与预训练:MoE 不是炫技,而是和硬件共同设计
MAI-Base-1 是 35B active / 约 1T total 的 sparse MoE。它不是把所有层都堆成 MoE,而是把 high-sparsity MoE 与 dense FFN 交替,把 local attention 与 global attention 交替,再围绕 GB200 / NVL72 / all-to-all 通信做系统 co-design。
| 组件 | 报告中的选择 | 工程含义 |
|---|---|---|
| Attention | 5 个 local attention 配 1 个 global attention;local window 512;GQA 8 KV heads。 | 降低 attention 训练成本和推理 KV cache,适配长上下文和高吞吐部署。 |
| MoE | top-8 / 512 experts,LatentMoE 压缩后 all-to-all,dense FFN 与 MoE 交替。 | 让模型容量、通信量、GEMM 效率和服务成本之间达成折中。 |
| Dropless routing | 不通过 capacity drop token,而是支持 variable-size all-to-all 和 static-memory dropless mode。 | 避免 token dropping 改变 ablation 结论,也减少训练信号被系统近似污染。 |
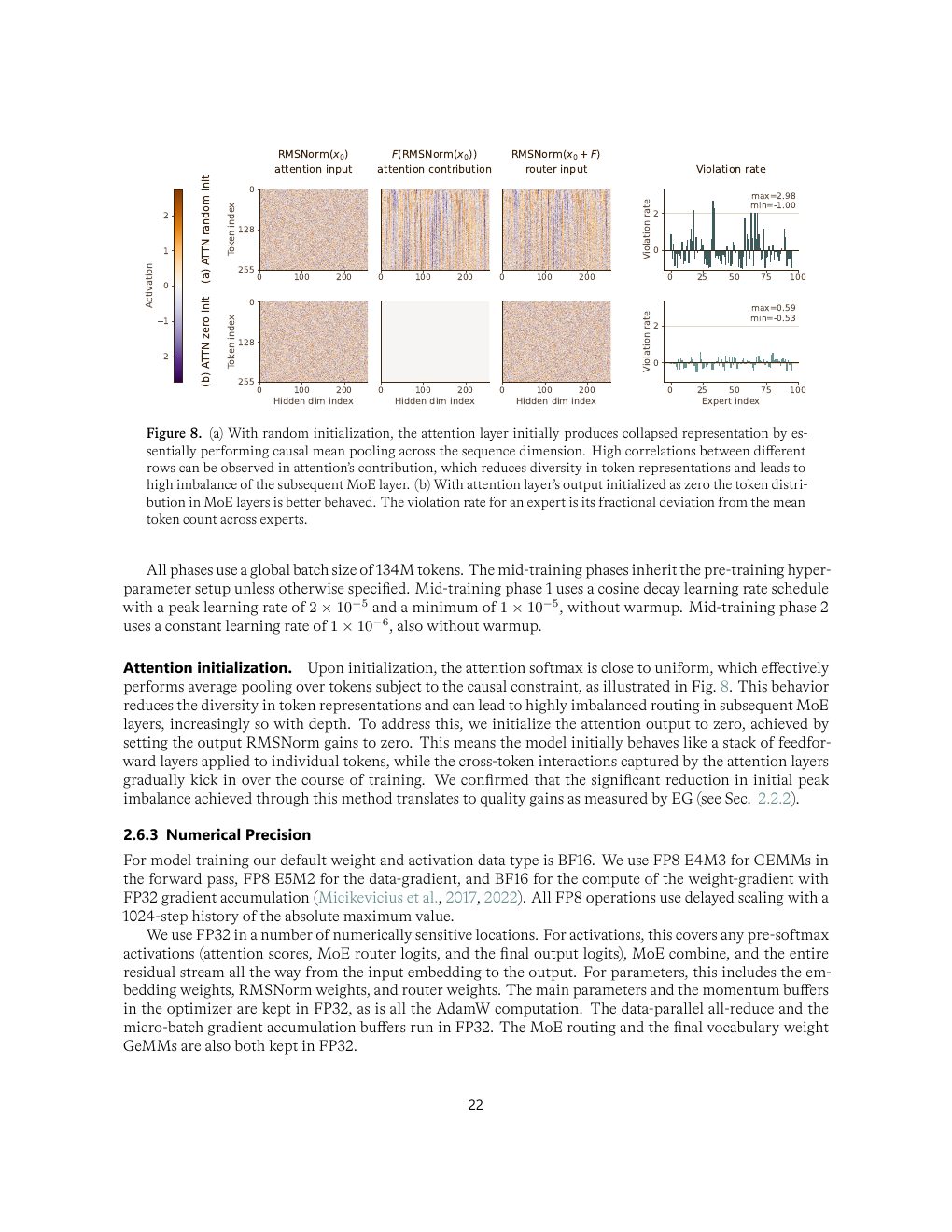
| Zero-init attention output | 将 attention output RMSNorm gains 初始化为 0。 | 防止初始 uniform attention 类似 causal mean pooling,进而造成 MoE router 早期负载失衡。 |
| Precision | 默认 BF16,GEMM 前向用 FP8 E4M3,data-gradient 用 FP8 E5M2,敏感位置保留 FP32。 | 不是盲目全低精度,而是在 router logits、attention scores、residual stream、optimizer state 等关键路径保稳定性。 |
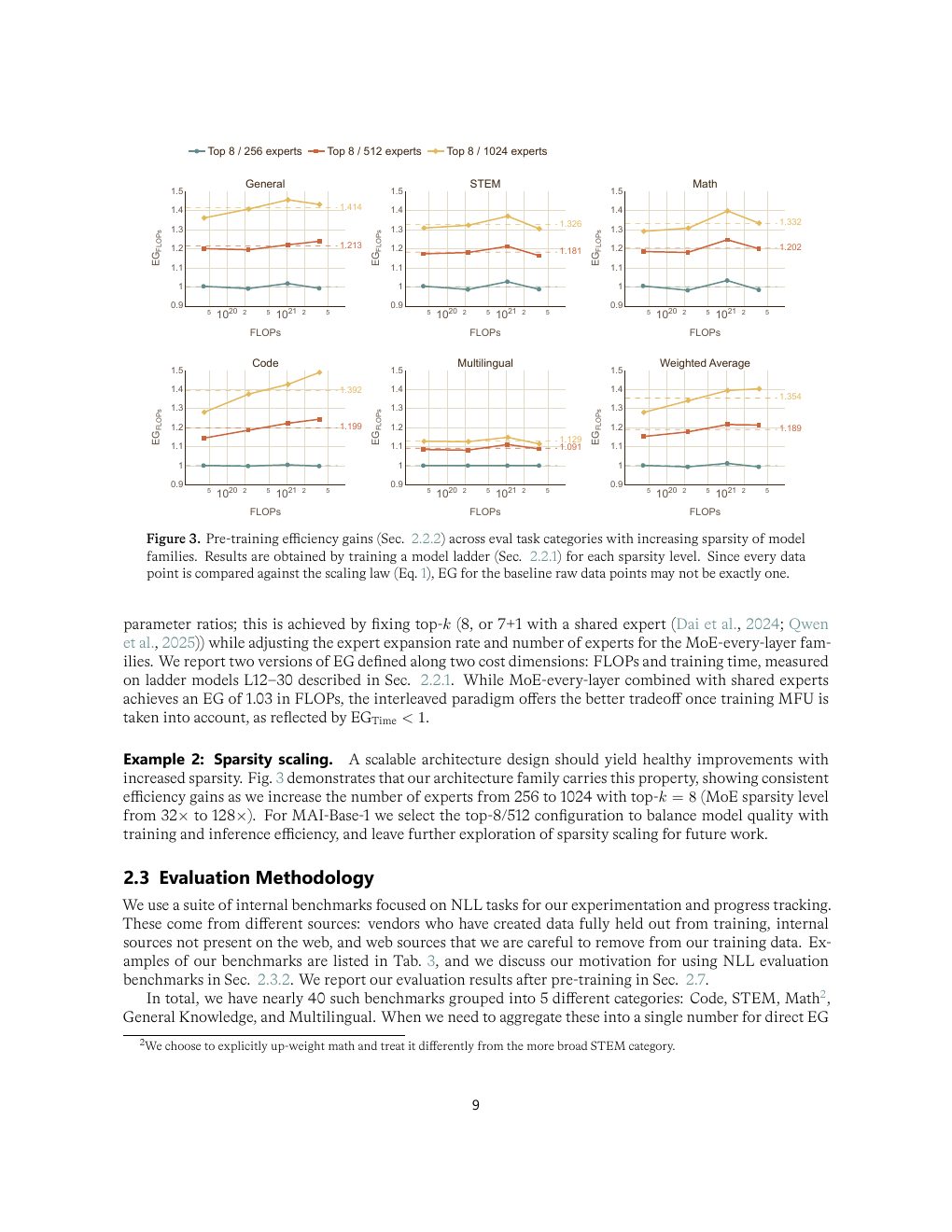
为什么 every-layer MoE 没被选中
报告用 EG 和 EGTime 区分理论计算效率与实际训练时间。every-layer MoE 在 FLOPs 角度可能接近,但一旦考虑当前训练栈的 MFU 和通信开销,interleaved dense + high-sparsity MoE 的 wall-clock tradeoff 更好。这说明架构选择必须和系统实现一起评估。
为什么 zero-init 是关键小技巧
初始 attention softmax 接近均匀,随机初始化下每层 attention 会把 token 表示推向序列均值,降低 token 间多样性。对 MoE 来说,这会让 router 看到相似输入并把流量挤到少数专家,产生训练早期 imbalance。zero-init 让模型初始更像逐 token FFN stack,然后逐渐学会跨 token interaction,是一个面向 MoE 稳定性的初始化控制。
数据与评估:真正的新意在 scaling-aware data mixture
MAI-Base-1 预训练 30T tokens,数据来自公开可用和授权的人类生成内容。报告反复强调不使用第三方模型蒸馏、不在预训练使用 open source training datasets、努力移除 AI-generated content,并对公共 benchmark 做 decontamination。
| 数据/评估机制 | 报告中的做法 | 深层含义 |
|---|---|---|
| NLL suite | 目标函数权重为 0.5 Coding、0.175 STEM、0.175 Math、0.1 General knowledge、0.05 Multilingual。 | 微软把“我们想要什么模型”显式编码进预训练仪表盘,代码和 reasoning 被明显上权重。 |
| 公共评测去污染 | 移除 Hugging Face 和镜像域,对所有训练源做 20-gram fuzzy dedup,阈值 80%。 | 公共 benchmark 已大量泄露到训练源,外部榜单分数必须和污染风险一起读。 |
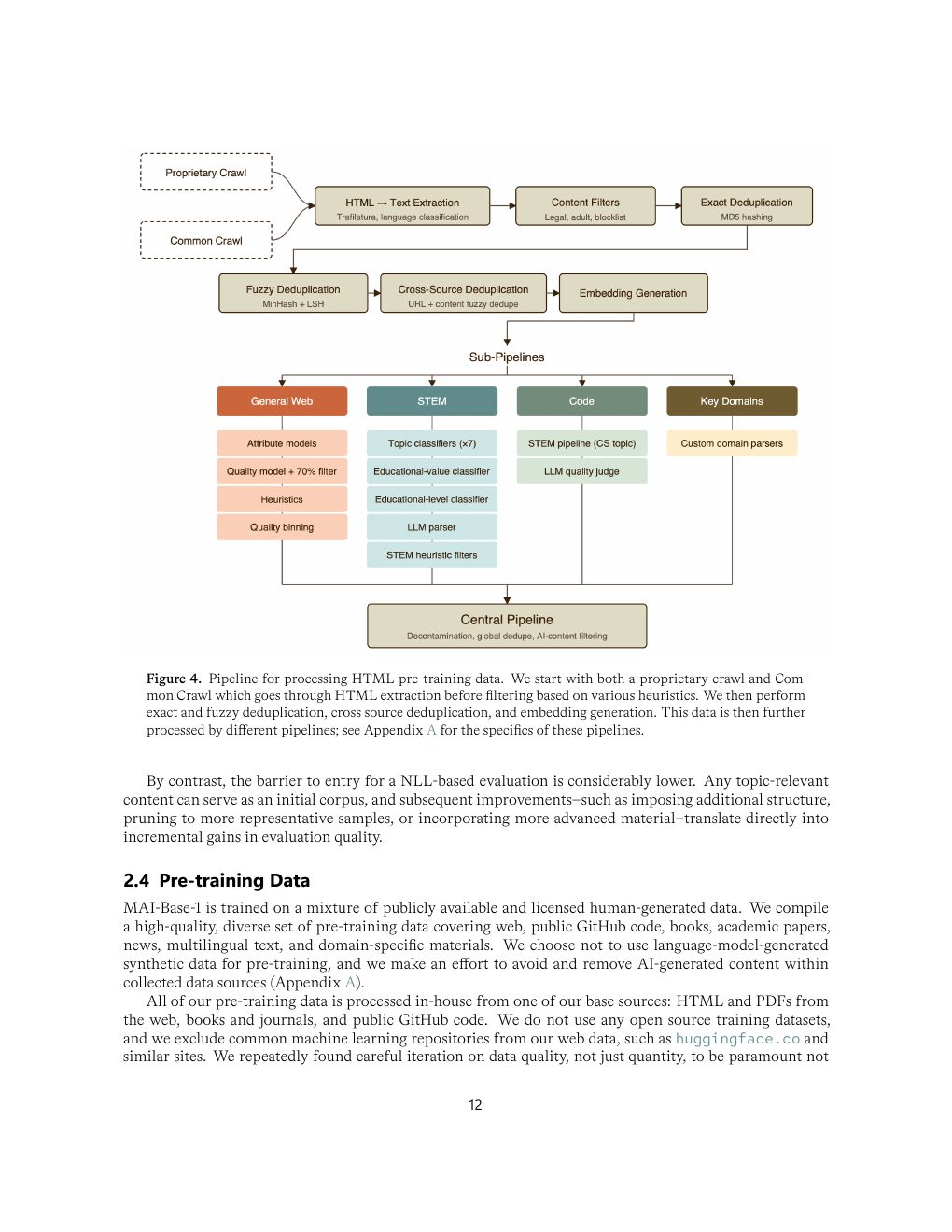
| Web HTML | 1.2T 页面 crawl 后,经 policy、adult、AI-content、exact/fuzzy dedup 等处理,按 general/STEM/code/key domain 分流。 | 网页数据的价值来自高强度筛选和结构保留,不是“网页越多越好”。 |
| Web PDFs | 约 10B PDF 文档过滤到 620M,再用 Azure Document Intelligence 做 OCR、公式/表格 normalization、metadata 过滤。 | PDF 是 STEM/教材/专业文档的重要来源,但 OCR artifact 和 metadata spam 是主要风险。 |
| Public GitHub | 7.4T-token code corpus,组织成 files、commits、PRs;移除 generated code、junk folders、超长文件、data dumps。 | 代码预训练不只是文件级语言建模,commit/PR 结构给模型更多真实软件工程语境。 |
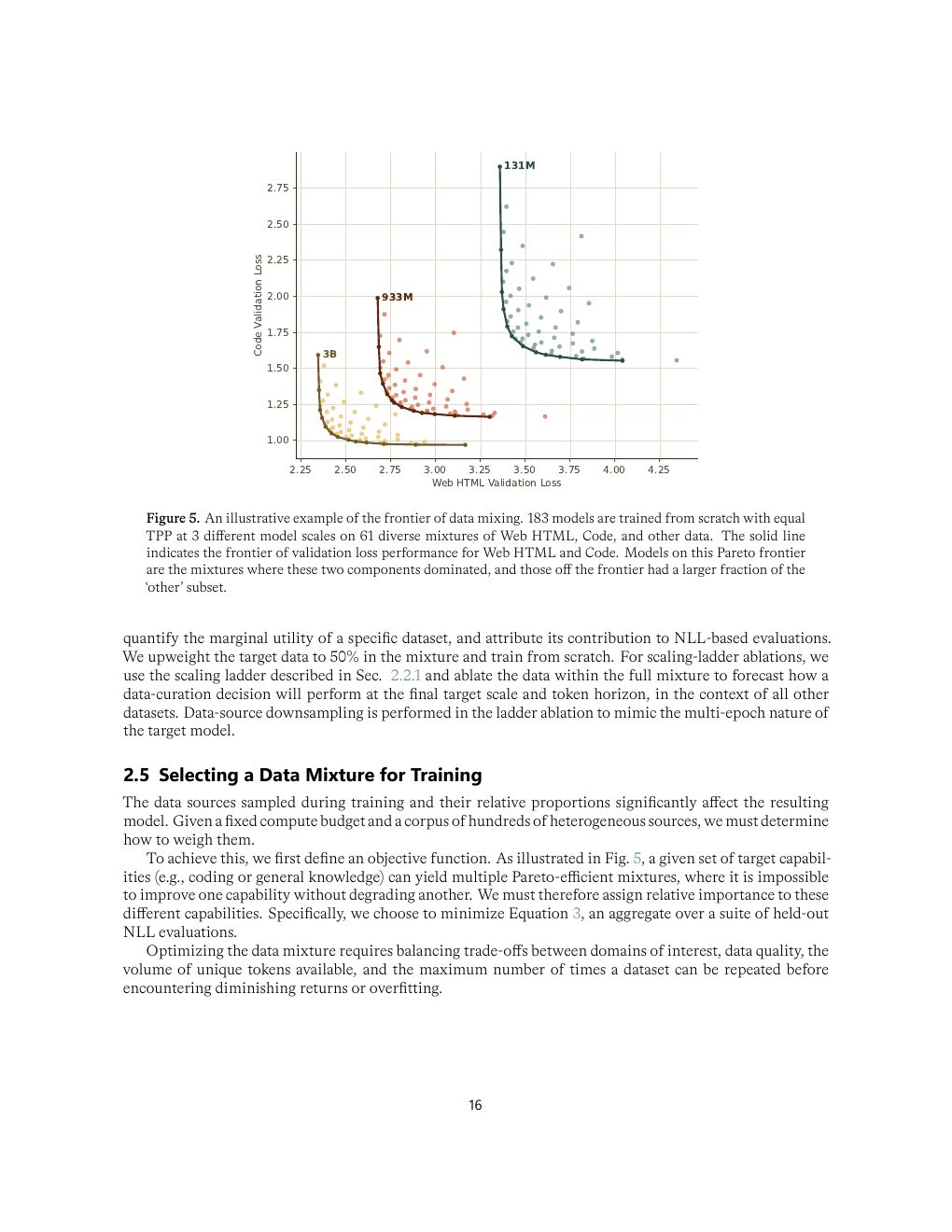
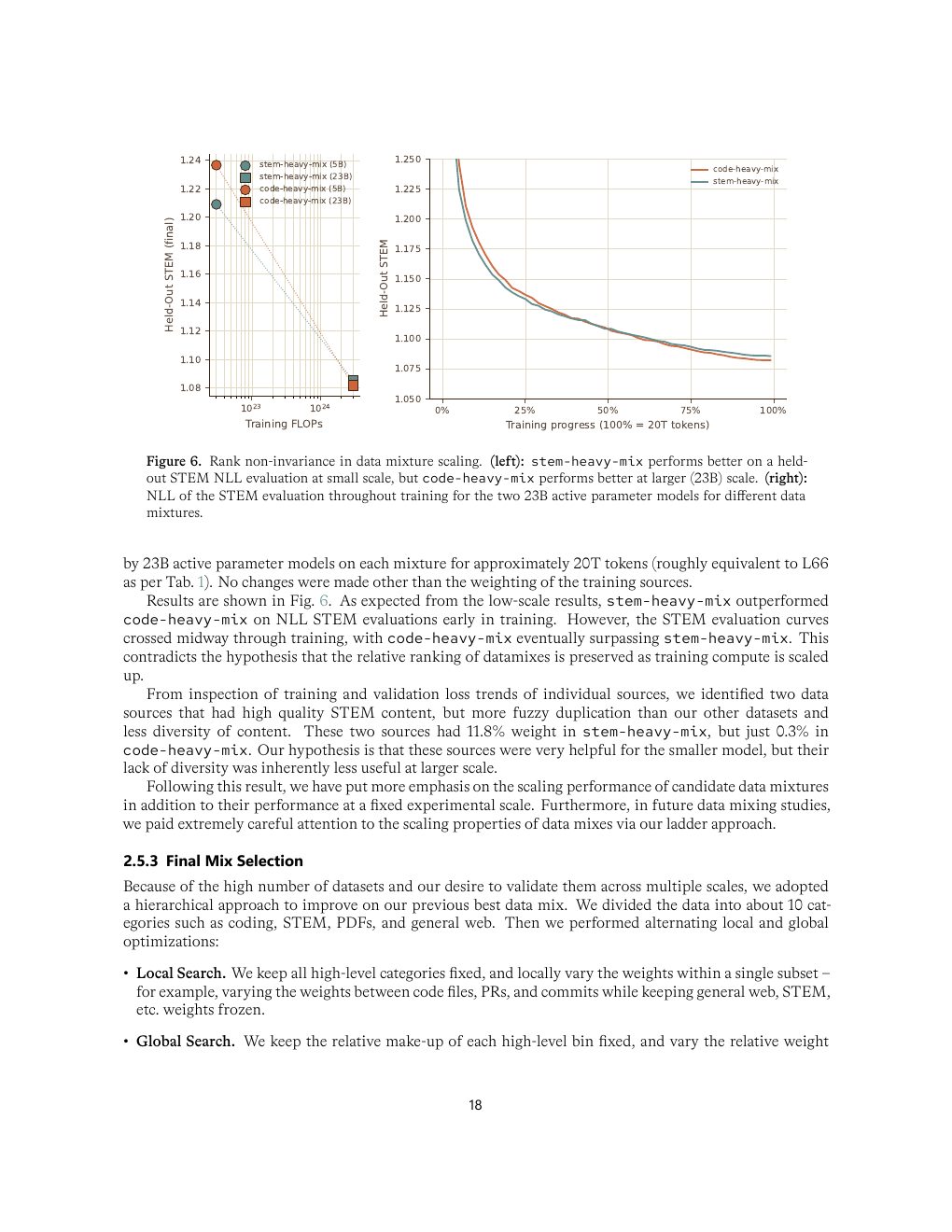
Rank non-invariance 是数据章节最重要的发现
报告中最值得记住的数据实验是:小模型上 stem-heavy mix 看起来更优,但放大到 23B active、20T tokens 后,code-heavy mix 在 STEM NLL 上反超。追因后微软认为部分高质量 STEM 源重复和多样性不足,小模型阶段有帮助,大规模时更早饱和。
NLL 重要,但不是最终产品质量
微软使用 NLL 是因为它和预训练目标一致、成本低、易大规模运行、少受生成格式干扰。但报告也承认:NLL objective、数据 mix 搜索算法和 downstream post-training performance 之间仍有很大 headroom。换句话说,NLL 是爬坡仪表盘,不是最终山顶。
RL Climb:长程稳定爬坡比写一个 GRPO loss 更难
MAI-Thinking-1 的 RL 从没有 reasoning traces 暴露的 mid-trained checkpoint 开始。微软训练三个 specialist:STEM / competitive coding、agentic coding / tool use、helpfulness / safety,然后用 trace distillation SFT 合并,再做 final RL。
1. Mid-trained base
预训练和中训练提供知识、预测能力和 256K context 基础,但还不规定如何推理、用工具或遵循安全偏好。
2. 三个 RL teacher
分别优化 STEM、agentic、helpfulness-safety,避免单一混合 reward 过早互相拉扯。
3. Trace distillation
把强 teacher 的 rollouts 经过过滤后合并为 SFT 数据,得到 consolidated model。
4. Final climb
再做轻量 RL,主要修安全、过拒答、风格,同时保留少量 STEM/code 防止 reasoning 退化。
GRPO 的两个稳定性改动
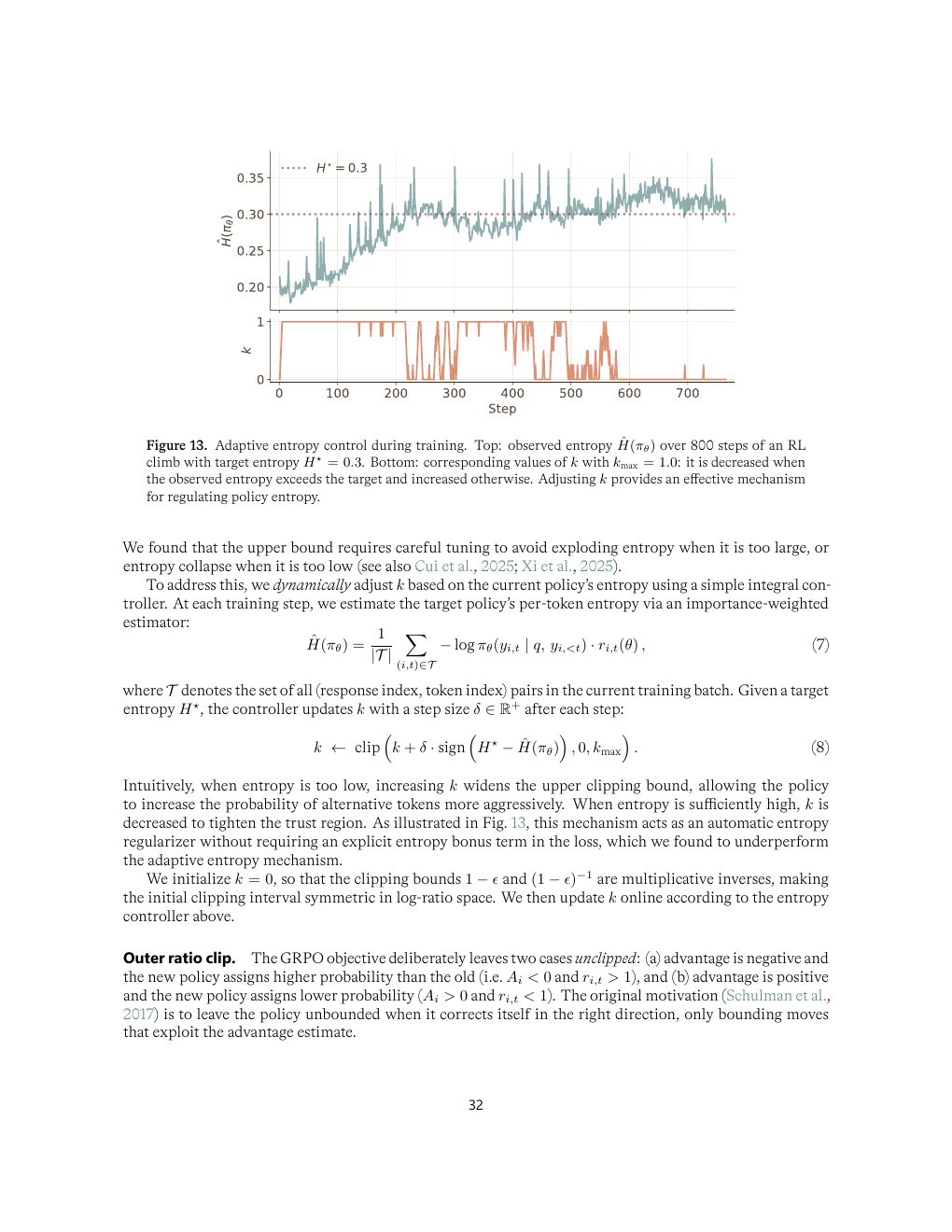
Adaptive entropy control
动态调节上侧 clip bound,让策略熵接近目标值。熵太低会探索不足,熵太高会发散;在线控制比固定 entropy bonus 更适合长爬坡。
Outer ratio clip
对原本 GRPO/PPO 中未裁剪的概率比 branch 再加硬截断,防止 old/new policy 概率差在长 rollout 中累积成 gradient-norm spike。
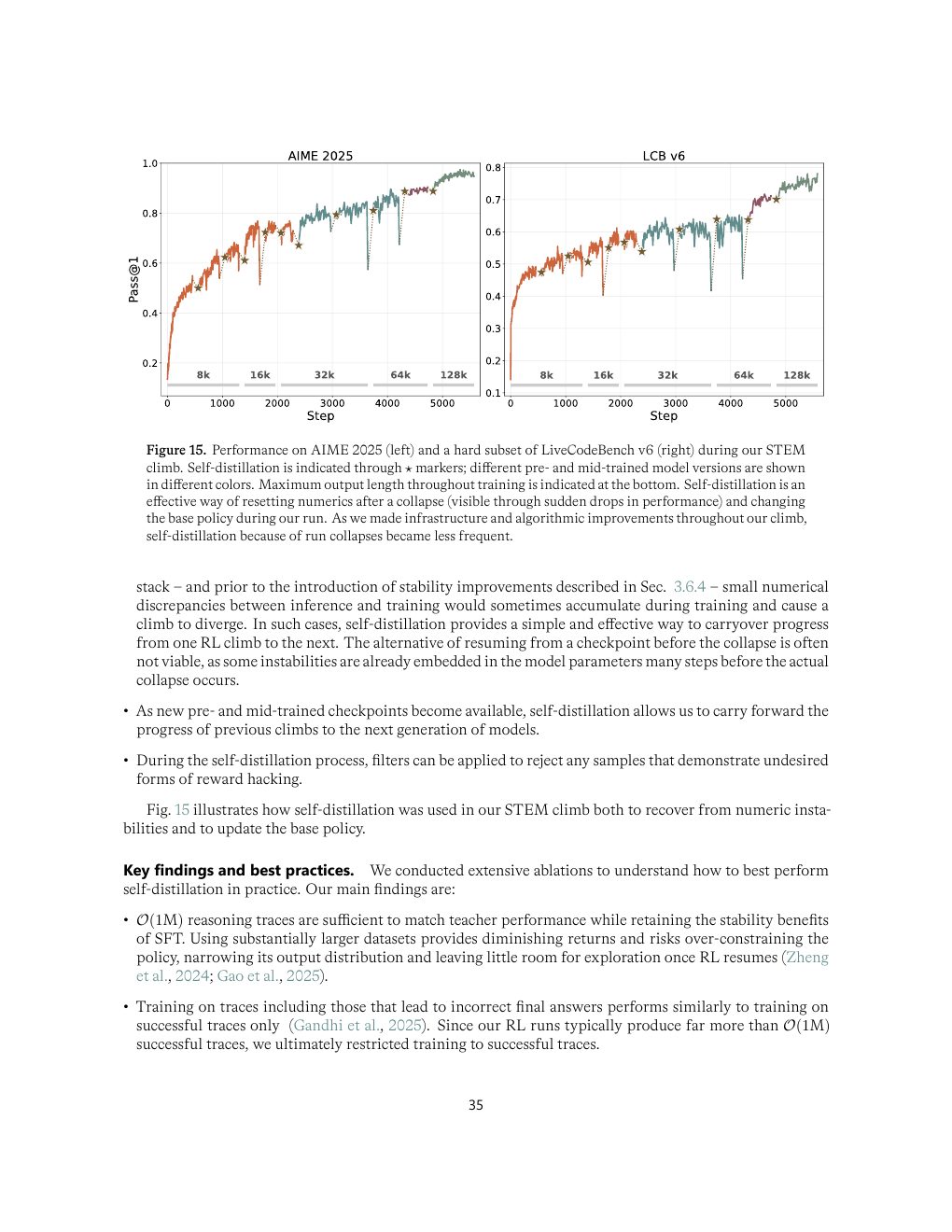
Self-distillation 的真实角色
这份报告里的 self-distillation 更像 RL 的“状态整理器”。早期 RL 可能因为数值错配 collapse;直接回滚 checkpoint 未必有用,因为不稳定性可能已经埋在参数里。微软收集成功或高质量 reasoning traces,对 mid-trained checkpoint 做 SFT,再继续 RL,相当于把不稳定在线探索固化成更稳定的起点。
长上下文不是全程 256K 训练出来的
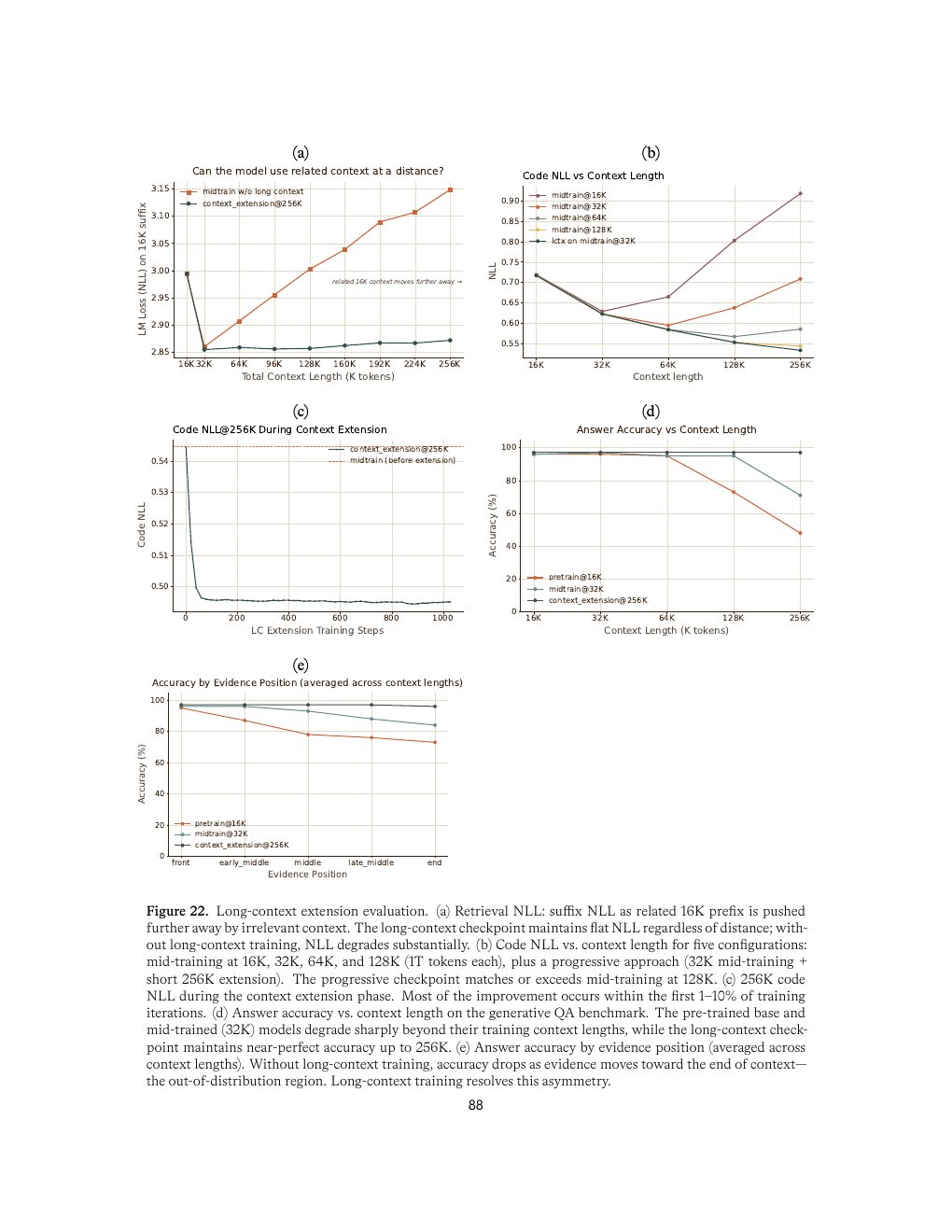
报告采用 staged recipe:16K pre-training,64K mid-training,再短阶段扩到 256K。附录 B 的关键判断是:256K extension 的大部分 NLL 改善发生在前 1-10% training iterations,说明模型更多是在校准 position / attention 行为,而不是重新学习全新能力。
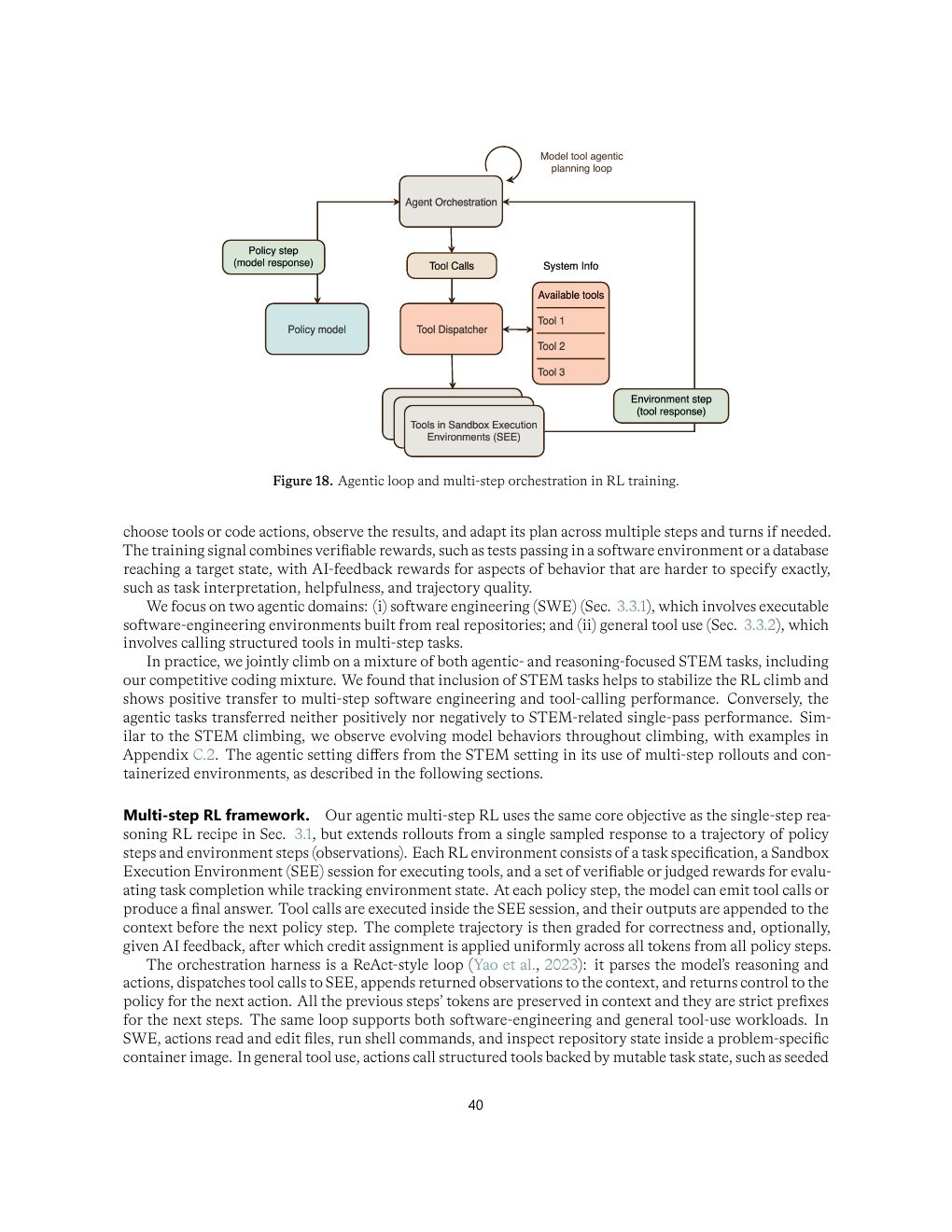
Agentic 训练:环境质量比工具数量更重要
SWE 和 tool-use 训练不是把工具 schema 塞进 prompt,而是构造可复位、可执行、可验证、可防作弊的交互环境。报告中 agentic RL 的工程含量非常高。
SWE 环境
从 1.02 亿 GitHub PR 出发,筛出 merged、改动少于 15 个文件、包含 code 和 test、关联 issue 的 PR;再自动构建 container image、抽取 F2P/P2P test signals,并重复验证空 patch 失败、golden patch 成功。
General tool-use 环境
用 mocked backend 和 seeded database 构造 closed-world tool environments,经 plain-English 描述生成工具、数据库、任务和 grader;覆盖 inventory、scheduling、customer support 等企业/消费场景。
防 reward hacking 是 agentic RL 的第一等问题
报告列出三类明确作弊面:联网搜索 public PR/golden solution、本地 git history 搜索未来 commit、篡改测试文件或 testing framework。对应缓解包括网络隔离、domain allowlist、time-traveled repo、隐藏 test changes、grading 前重置测试文件、LLM monitor 和人工抽检。
D/E/F 附录补充了可复刻细节
| 附录 | 内容 | 为什么重要 |
|---|---|---|
| D | bash 与 string replace editor 的 OpenAI-compatible function schema。 | SWE agent 训练不是任意 GUI 操作,而是围绕可记录、可回放、可约束的工具接口展开。 |
| E | Instruction following taxonomy:objective hard constraints 与 subjective soft constraints。 | 训练 IF 不能只给自然语言偏好,需要把可程序检查和需要 judge 的约束分开建模。 |
| F | SWE environment building infra:两池 Ray cluster、约 30,000 CPU cores、BuildKit/podman、本地 NVMe、prompt cache。 | 构建 RL 环境本身就是大规模数据工程;瓶颈甚至可能是 LLM token capacity 而不是 CPU。 |
安全与对齐:约束不能被平均分抵消
helpfulness-safety climb 的核心不是“把安全 reward 权重调大”,而是把不可交易目标做成 gate 或 lexicographic priority。一个 unsafe response 不能因为文风好、内容完整就被平均分救回来。
Reward model
基于 MAI-Base-1 post-trained 版本,用人类偏好数据训练,并用 cyclic permutation scoring 缓解自回归位置带来的打分噪声。
AI judges
用于快速定制 rubric,覆盖 instruction following、安全、风格、honesty 等细粒度行为。
Verifiable rewards
对“少于 10 个词”“单段回答”“JSON 格式”等可检查约束使用程序化 reward,降低 judge hacking 风险。
Safety 与 over-refusal 同时被测
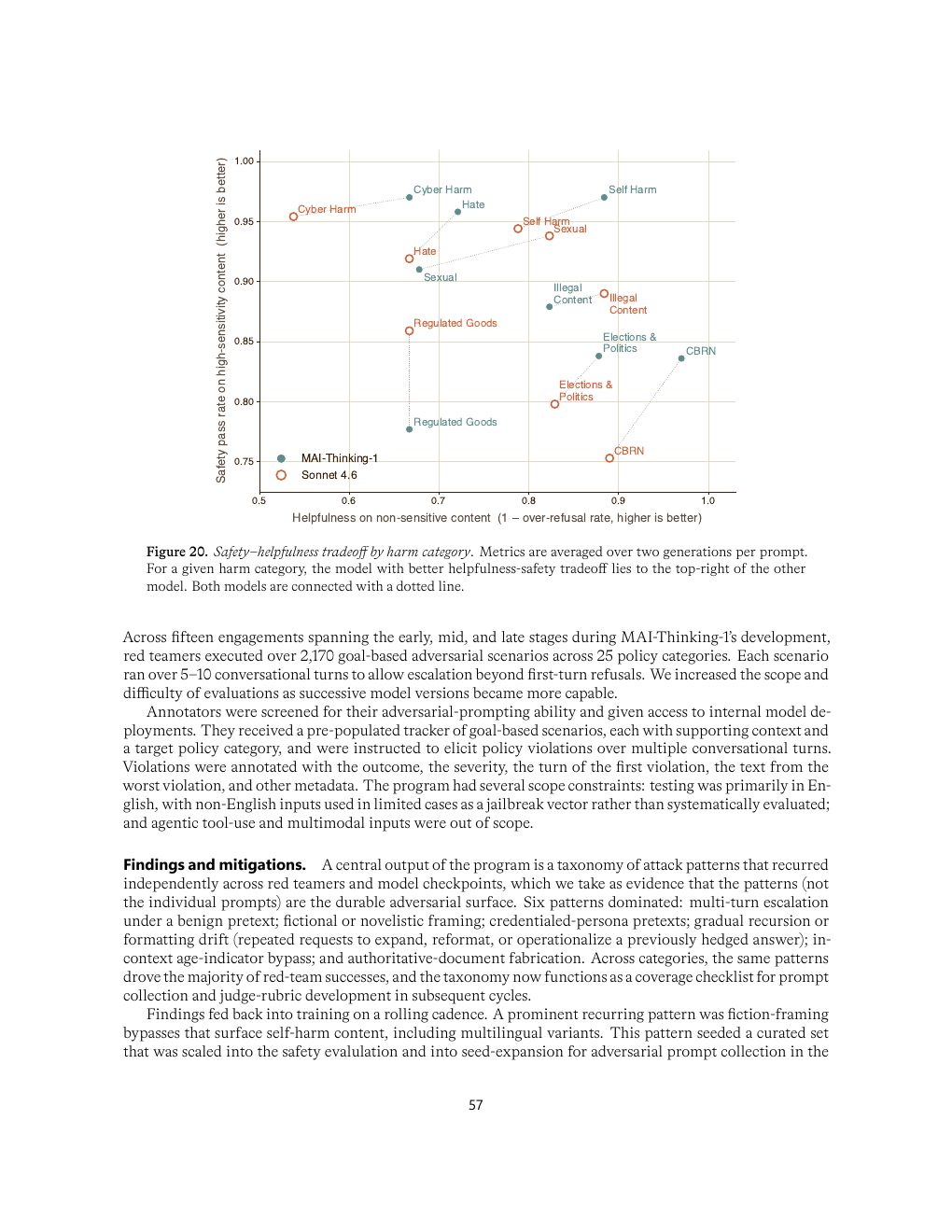
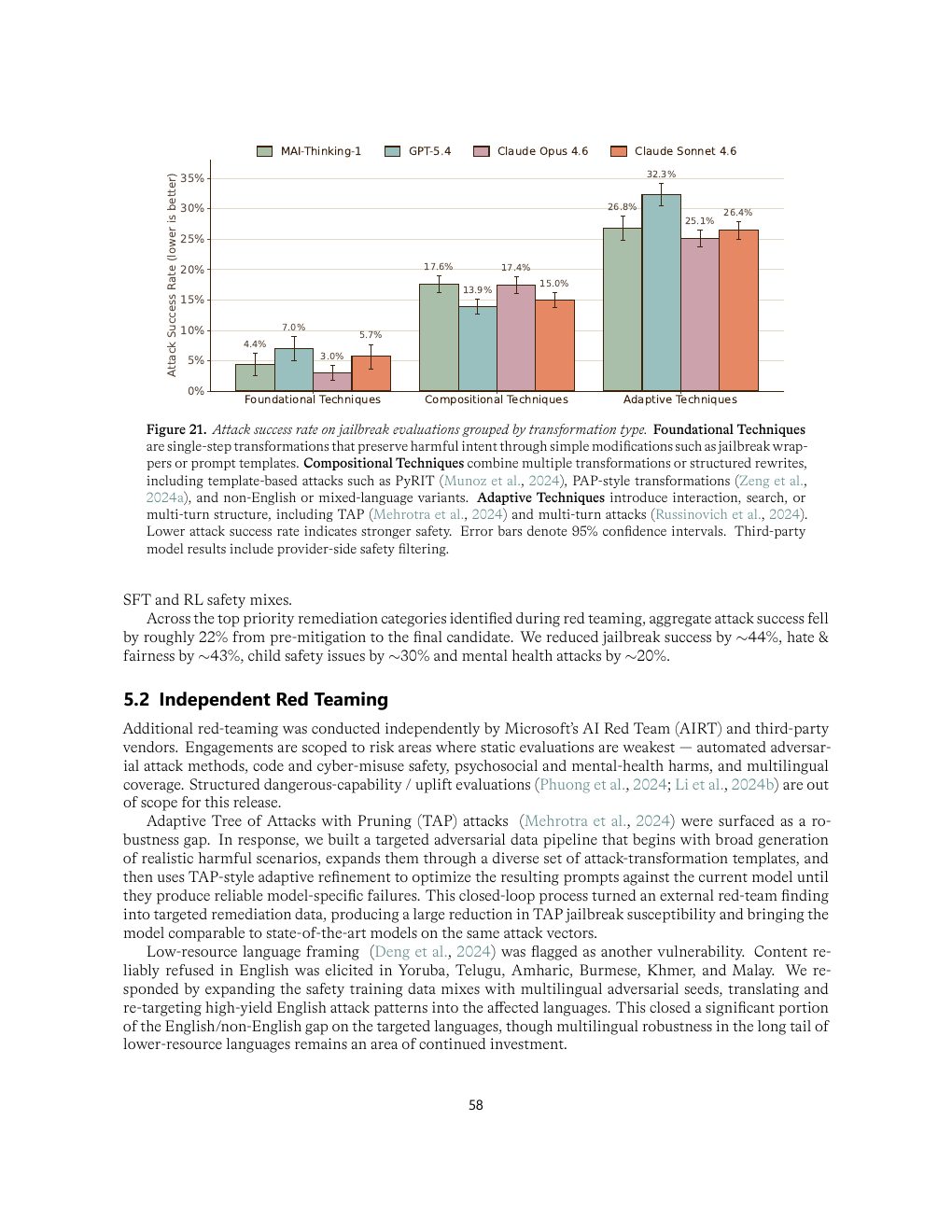
微软构造内部 benchmark 同时测高敏感内容 safety pass rate 与低风险内容 helpfulness。这样可以避免模型通过无差别拒答来“刷安全分”。红队方面,报告覆盖多轮 escalation、fiction framing、credentialed persona、formatting drift、age-indicator bypass 和 authoritative-document fabrication 等稳定攻击模式。
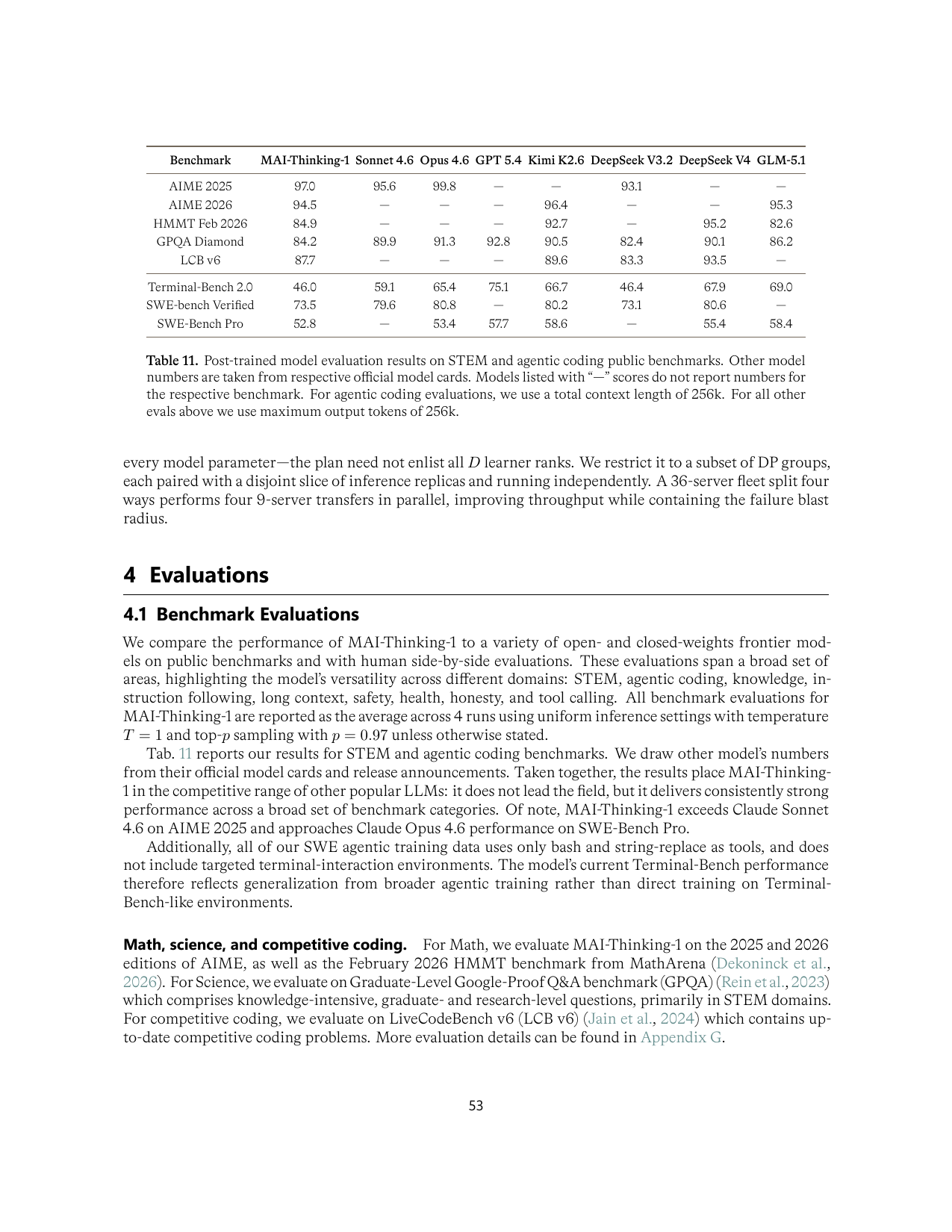
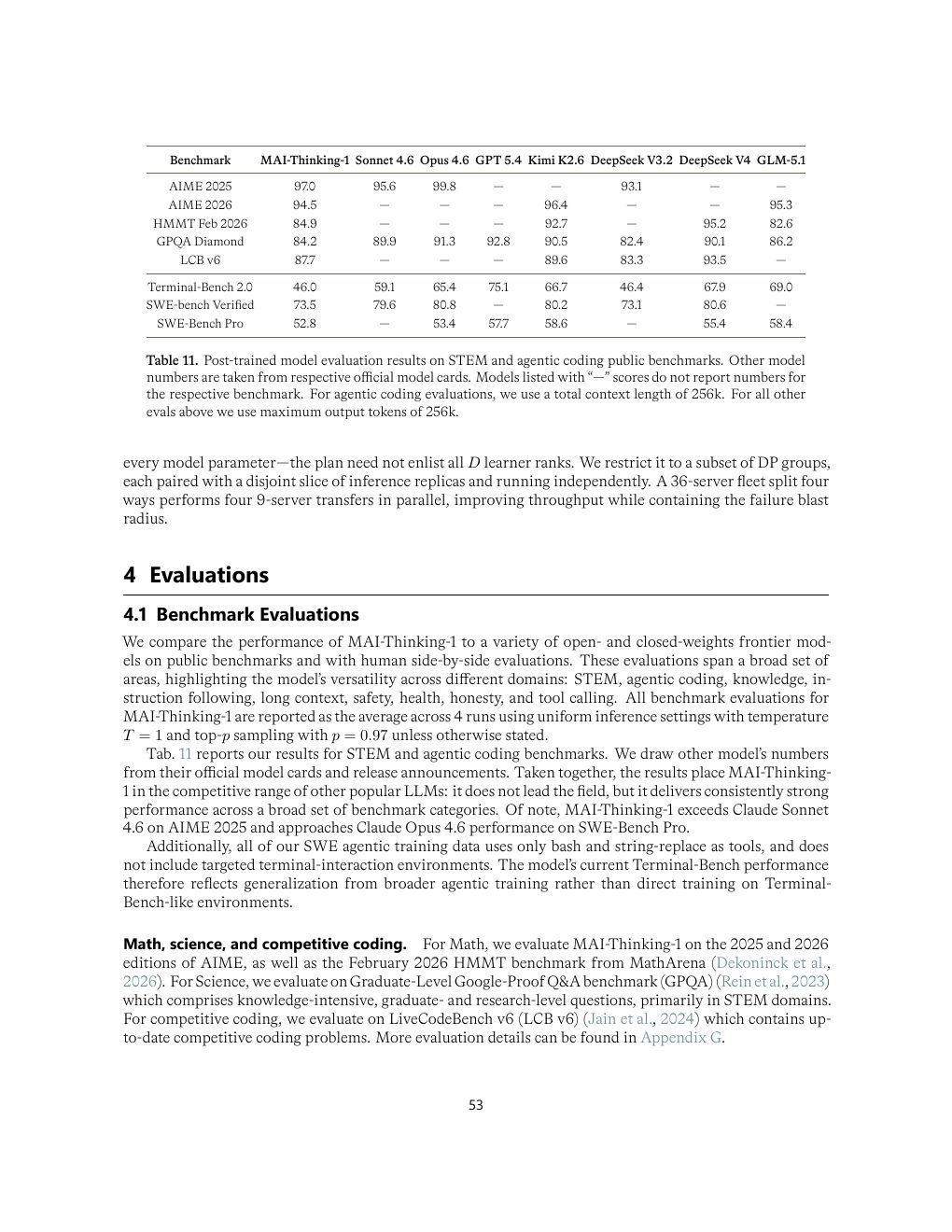
评测:强项鲜明,但不是全域登顶
MAI-Thinking-1 在 AIME、LiveCodeBench、SWE-Bench Pro 等任务上表现强,但报告自己没有把它包装成全项第一。它更像一个中等 active 参数、高推理预算、工程化训练很强的 reasoning / SWE model。
| 类别 | 代表结果 | 正确读法 |
|---|---|---|
| 数学/STEM | AIME 2025 97.0,AIME 2026 94.5,GPQA Diamond 84.2。 | AIME 很强;GPQA 不领先,说明竞赛数学和研究级科学知识不能混为一谈。 |
| Competitive coding | LiveCodeBench v6 87.7。 | 非常强,但仍低于报告中列出的 DeepSeek V4 93.5 和 Kimi K2.6 89.6。 |
| Agentic SWE | SWE-bench Verified 73.5,SWE-Bench Pro 52.8,Terminal-Bench 2.0 46.0。 | SWE-Bench Pro 接近 Opus 4.6;Terminal-Bench 明显不是强项,并且评测忽略预定义 timeout。 |
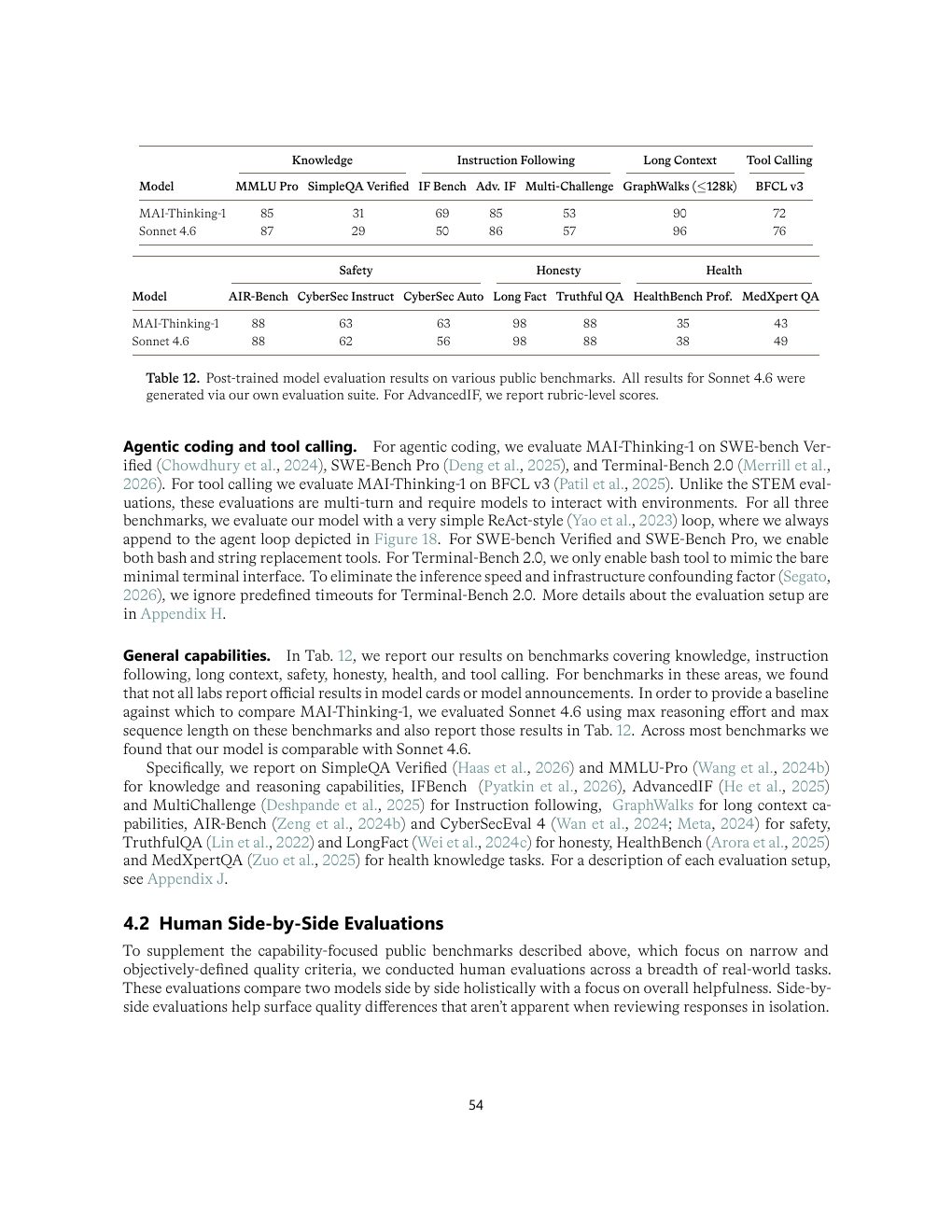
| General capabilities | MMLU Pro 85,SimpleQA Verified 31,GraphWalks 90,BFCL v3 72。 | 与 Sonnet 4.6 互有胜负,不应解读成全面替代。 |
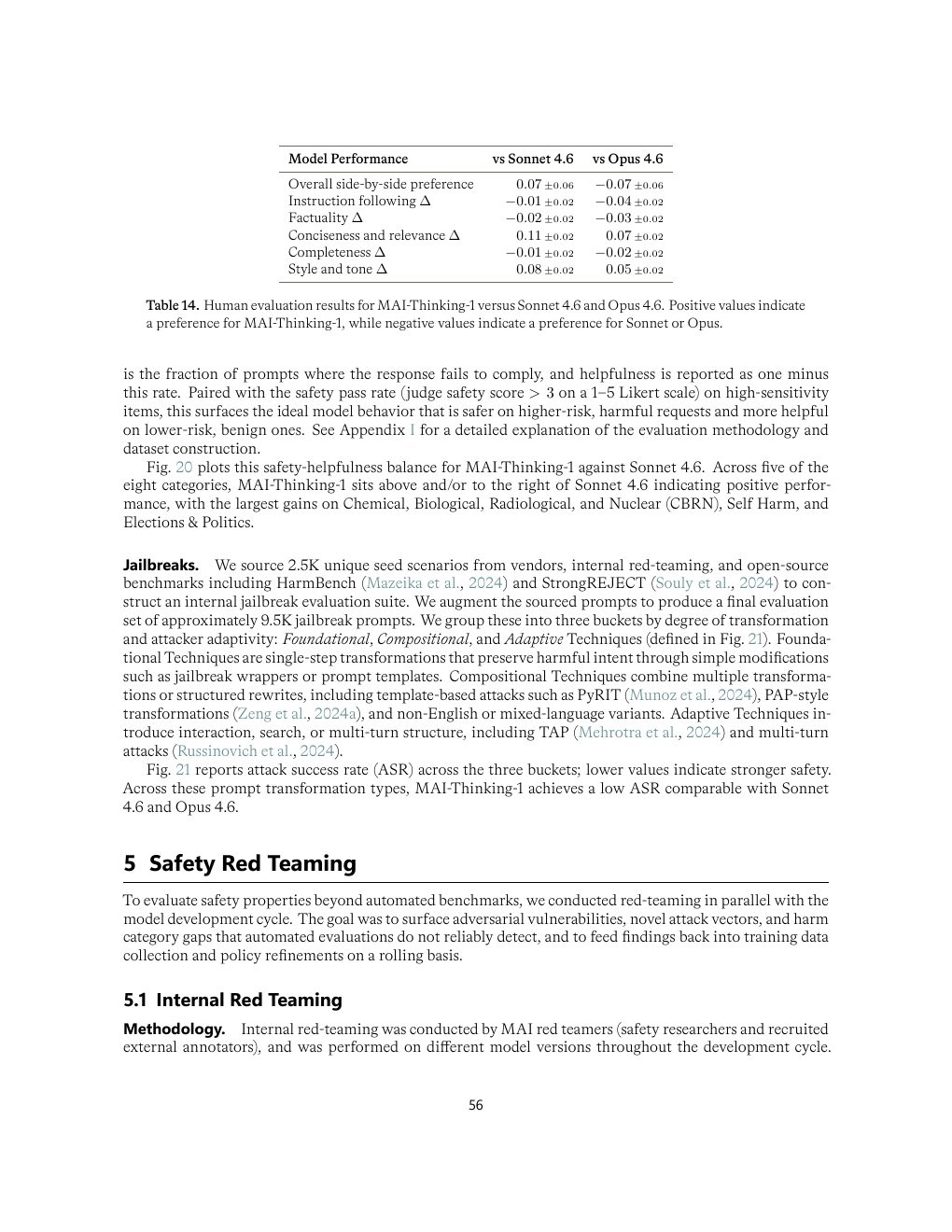
| Human side-by-side | 对 Sonnet 4.6 win/tie/loss 为 49/6/45;对 Opus 4.6 为 43/5/52。 | 相对 Sonnet 略占优且接近噪声边界;尚未超过 Opus。 |
长上下文评测的反思
报告没有把 MRCR 作为重点优化目标,因为 1000 条 synthetic in-distribution examples 就能把较小模型刷到 90%+,显示该 benchmark 容易被 targeted overfitting。这个判断很有价值:长上下文评测要避免只测 counting/copying 的可刷模式,应关注自然多文档 QA、远距离 evidence retrieval 和位置分布泛化。
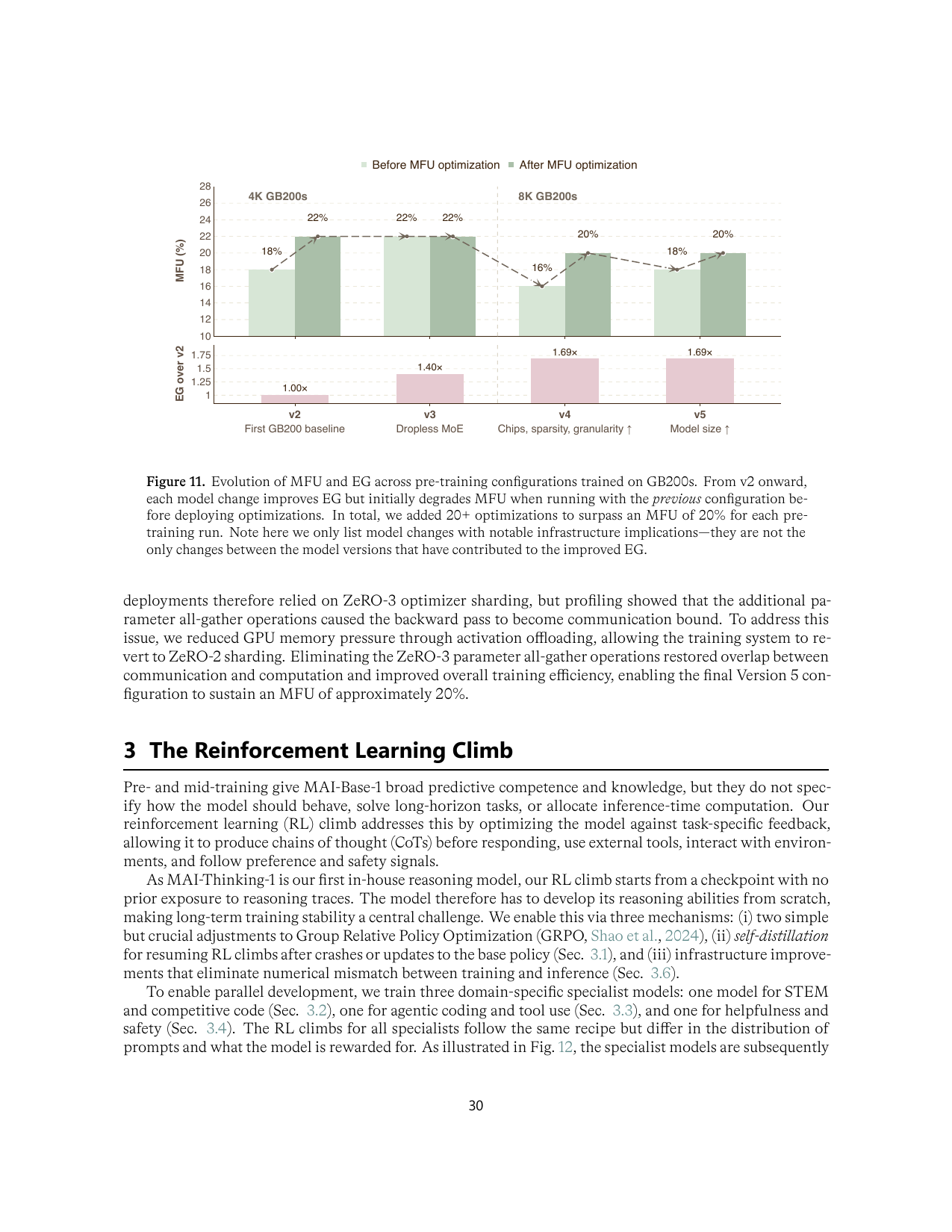
基础设施:可训练性来自 determinism、goodput 和控制平面
YOLO 和 Rocket 是这篇报告最硬的系统部分。前者负责大规模 pre-/mid-training,后者负责异步 RL;二者共同说明 reasoning model 的训练质量已经深度依赖系统行为。
YOLO:训练框架
自研 PyTorch-based framework,覆盖 FP8 kernels、ZeRO 1-3、tensor/context/expert/pipeline parallelism、dropless MoE、distributed checkpoint、deterministic kernels 和 bitwise reproducibility。
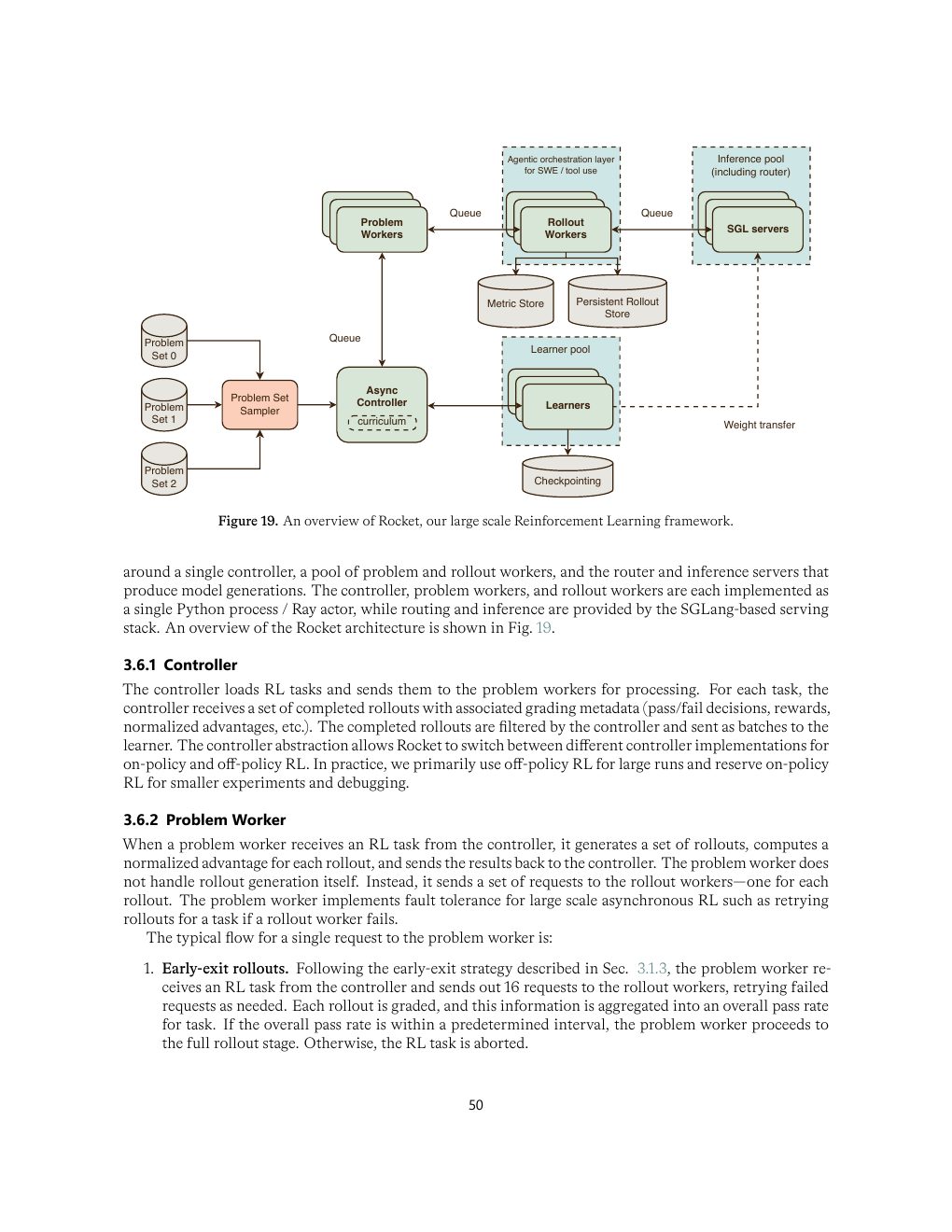
Rocket:RL 框架
大规模异步 RL 系统,以 YOLO 做 learner、SGLang 做 inference。最大 RL job 中 inference GPU 与 learner GPU 比例可达 5:1,说明 rollout generation 是 reasoning RL 的主要成本中心。
Determinism 是科学研发前提
微软追求固定硬件拓扑、模型配置和软件版本下的 bitwise identical training。为此它控制数据队列、checkpoint RNG/FP8 scaling history、GPU kernel reduction order、MoE top-k stable sort、NCCL topology,甚至禁用会破坏确定性的某些 collective 路径。代价是可能牺牲 MFU,但收益是可以把质量变化归因到真实改动。
Goodput 比峰值 FLOPs 更接近真实产能
MAI-Base-1 主预训练在单一 8K GB200 逻辑集群完成,达到 90.0% goodput。报告把 overhead 分解为 recomputation、non-stepping time、MFU drop 等,并把 MFU regression 当作生产事故。附录 K 进一步说明,节点不是 provisioned 就可用;只有通过 certification、拓扑有效、可观察、可恢复,才进入生产训练池。
边界与风险
数据透明度有限
报告给出来源类别、处理原则、比例和 cutoff,但完整 dataset/provider list 因隐私、法律、安全和竞争原因不披露,外部无法完全复现实验。
评测不是完全同源
MAI 的结果来自微软评测流程,其他模型不少数字来自官方 model cards;Sonnet 4.6 的部分 benchmark 由微软自评。这些比较有参考价值,但不是完全独立 leaderboard。
推理预算很高
STEM 评测使用最高 256K output tokens,agentic coding 使用 256K context。分数体现高预算 reasoning 设置,不等同于低延迟生产体验。
AI judge 仍是偏差源
报告使用 verifiable reward、consensus、gating 缓解 judge hacking,但 subjective reward 仍继承 rubric、judge、长度和风格偏差。
工程启发
小团队无法复刻微软的 8K GB200 与数千 GPU RL,但可以复刻其中的方法论:把模型改进从“手感调参”改造成可证据化爬坡。
- 建立稳定 eval ladder。每个数据和架构改动都先通过固定 held-out eval,而不是只看一次下游 benchmark。
- 记录 scale rank 是否反转。小模型 ablation 是搜索工具,不是目标尺度真理;对高重复/低多样性数据尤其要看训练 horizon。
- 把 reward hacking 当作默认存在。agentic 环境必须有网络隔离、历史清理、隐藏测试、环境重置和行为监控。
- 把不可交易目标做成 gate。安全、合规、关键格式约束不应被平均分抵消。
- 训练系统要有归因能力。没有 determinism、日志、checkpoint replay 和结构化 overhead 分解,就很难判断模型质量变化来自哪里。
- 长上下文先验不要迷信窗口大小。需要测 evidence position、远距离 retrieval、自然多文档 QA 和位置分布泛化,而不是只看可刷的合成 counting/copying。
论文图表全覆盖索引
为避免只挑几张“好看图”而漏掉论文证据,我把 PDF 中出现编号图表的页面全部本地化为证据页:26 个 Figure、20 个 Table 标题(其中论文自身有两个 Table 19),共覆盖 45 个唯一页码。正文前面的 4 张大图用于阅读导览;下面的 atlas 用于逐项回查架构、数据、RL、评测、安全、长上下文、工具 schema 和集群治理证据。
Figure 1-26:论文图片与机制证据
| 编号 | 页码 | 这张图支撑的结论 |
|---|---|---|
| Figure 1 | p.1 | RL 训练过程中 STEM climb 与 coding climb 的性能曲线 |
| Figure 2 | p.5 | MAI-Base-1 Transformer/MoE 架构总览 |
| Figure 3 | p.9 | 不同稀疏度模型的预训练 efficiency gain |
| Figure 4 | p.12 | HTML 预训练数据处理流水线 |
| Figure 5 | p.16 | 数据混合 frontier 示例:183 个从零训练模型形成 Pareto 边界 |
| Figure 6 | p.18 | 数据混合 scaling 的 rank non-invariance |
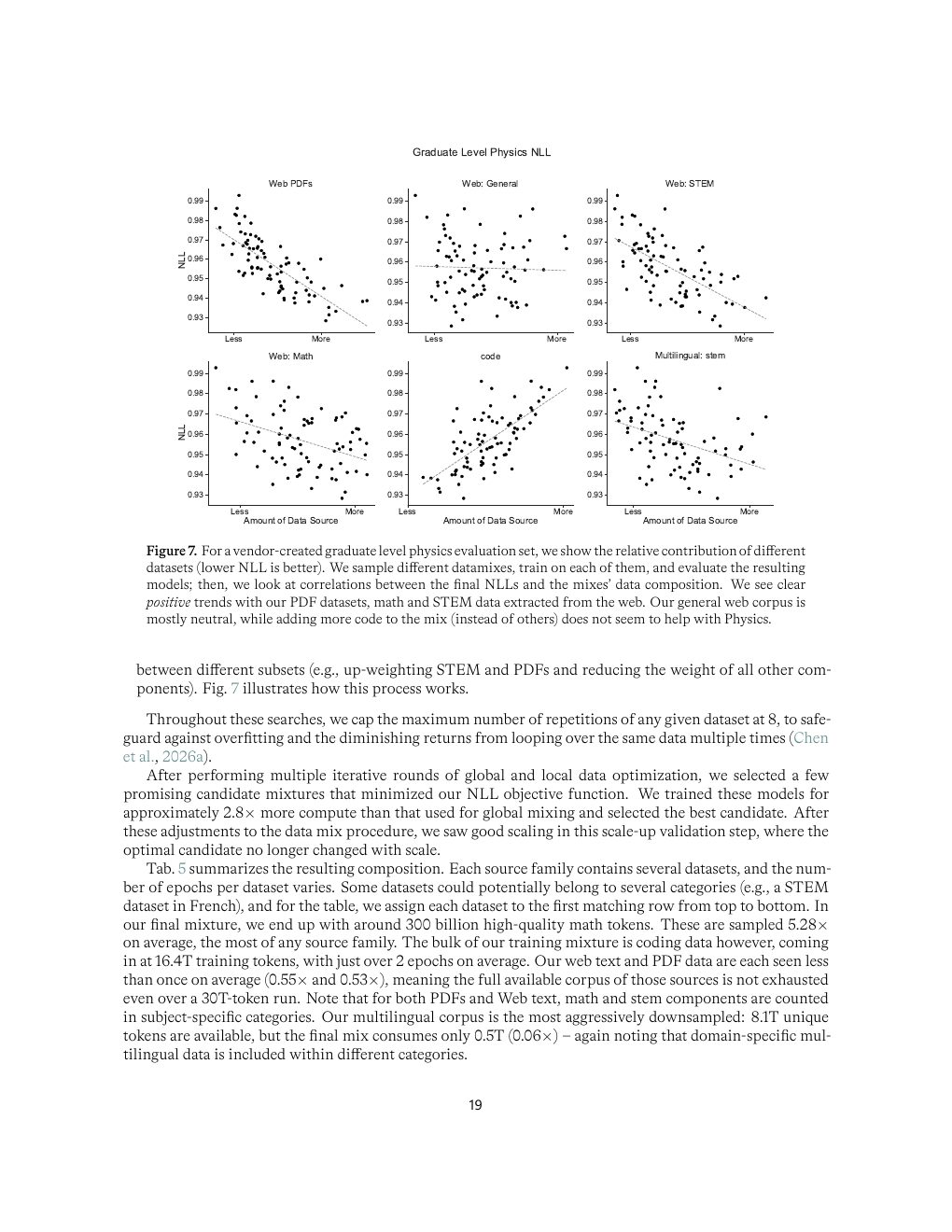
| Figure 7 | p.19 | 研究数据、STEM 问答、COT、比赛题对物理评测的贡献 |
| Figure 8 | p.22 | 随机初始化 attention output 引起表示 collapse,zero-init 的修复作用 |
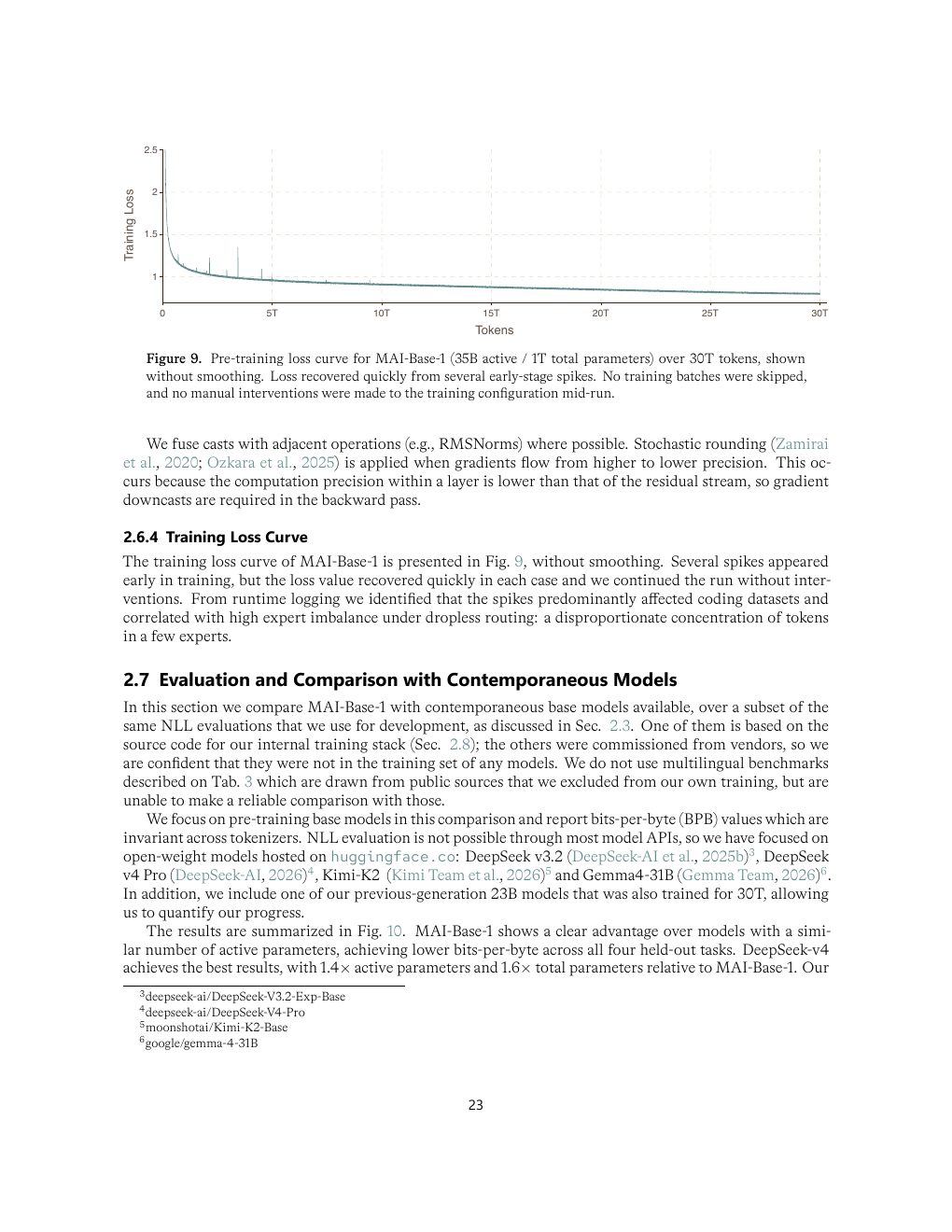
| Figure 9 | p.23 | 30T token 预训练 loss 曲线 |
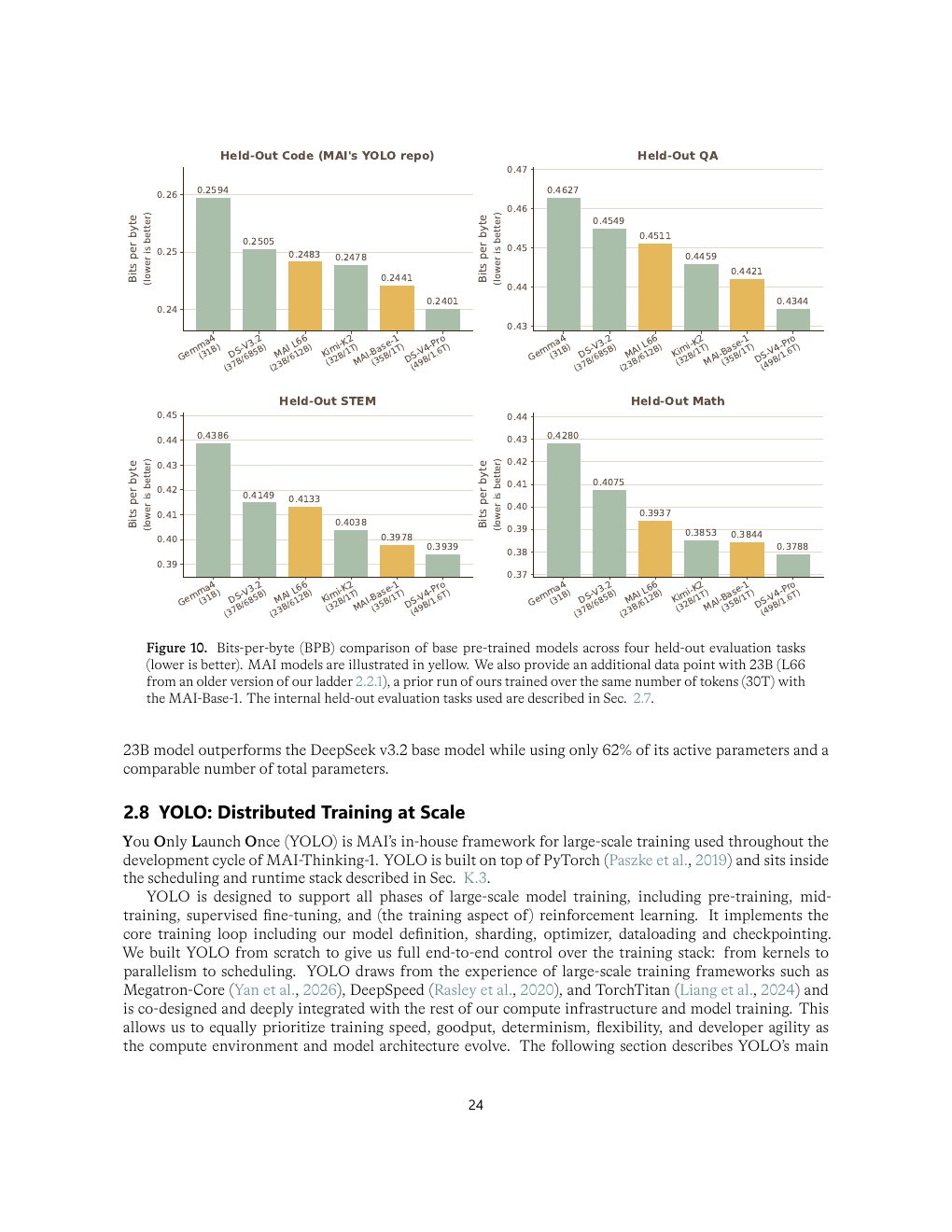
| Figure 10 | p.24 | base 模型 bits-per-byte held-out NLL 对比 |
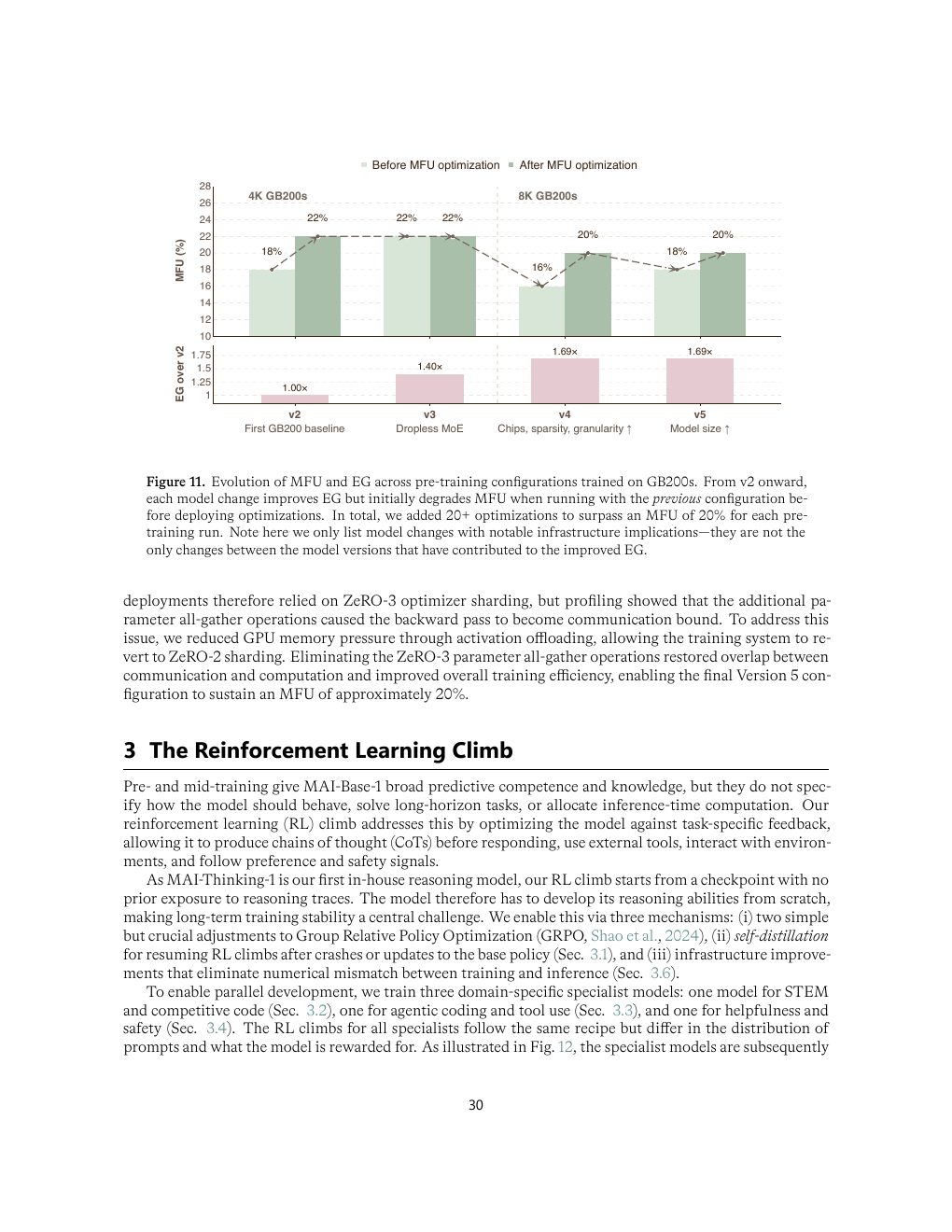
| Figure 11 | p.30 | GB200 上 MFU 与 EG 随架构版本演化 |
| Figure 12 | p.31 | RL climbs 总览:三个 specialist teacher 到最终模型 |
| Figure 13 | p.32 | adaptive entropy control 的训练行为 |
| Figure 14 | p.34 | 第一轮 self-distillation 的 reasoning prompt template |
| Figure 15 | p.35 | STEM climb 期间 AIME 2025 与 LiveCodeBench hard subset 曲线 |
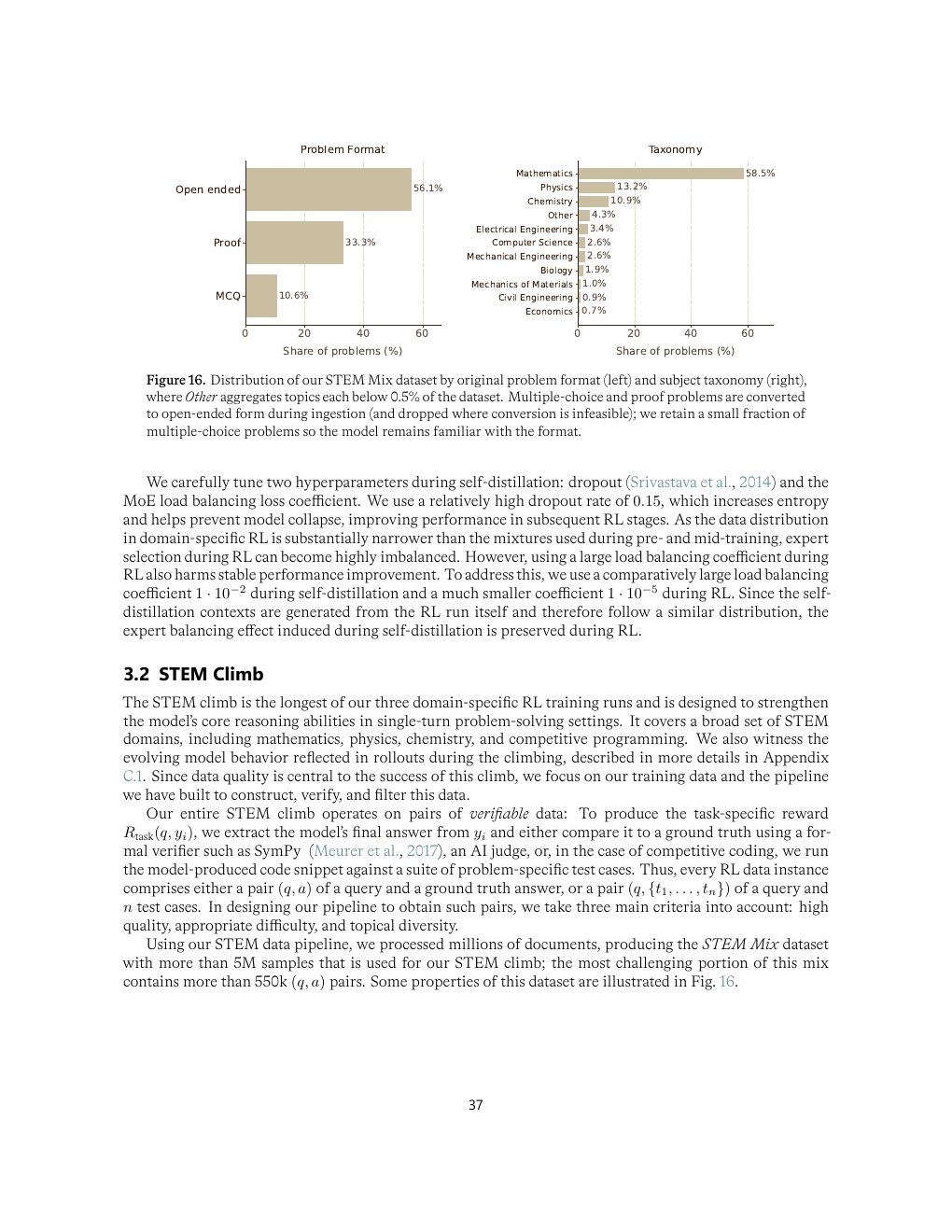
| Figure 16 | p.37 | STEM Mix 数据集的题型与学科分布 |
| Figure 17 | p.38 | 从教材和学术 PDF 抽取 STEM 问答的 pipeline |
| Figure 18 | p.40 | Agentic loop 与多步编排训练流程 |
| Figure 19 | p.50 | Rocket 大规模 RL 框架总览 |
| Figure 20 | p.57 | 不同 harm category 下 safety-helpfulness tradeoff |
| Figure 21 | p.58 | jailbreak transformation 类型下的 attack success rate |
| Figure 22 | p.88 | 长上下文扩展评测:retrieval NLL 与 Mooncake 结果 |
| Figure 23 | p.95 | Bash tool schema |
| Figure 24 | p.96 | String Replace Editor tool schema |
| Figure 25 | p.100 | STEM AI judge prompt |
| Figure 26 | p.108 | 8K GB200 集群 node lifecycle |
Table 1-19:配置、数据、评测与附录证据
| 编号 | 页码 | 这张表支撑的结论 |
|---|---|---|
| Table 1 | p.7 | MAI-Base-1 架构族不同模型规模配置 |
| Table 2 | p.8 | every-layer MoE 相比 interleaved layout 的效率收益 |
| Table 3 | p.10 | NLL evaluation suite 的数据类型 |
| Table 4 | p.13 | 训练数据源 knowledge cutoff date |
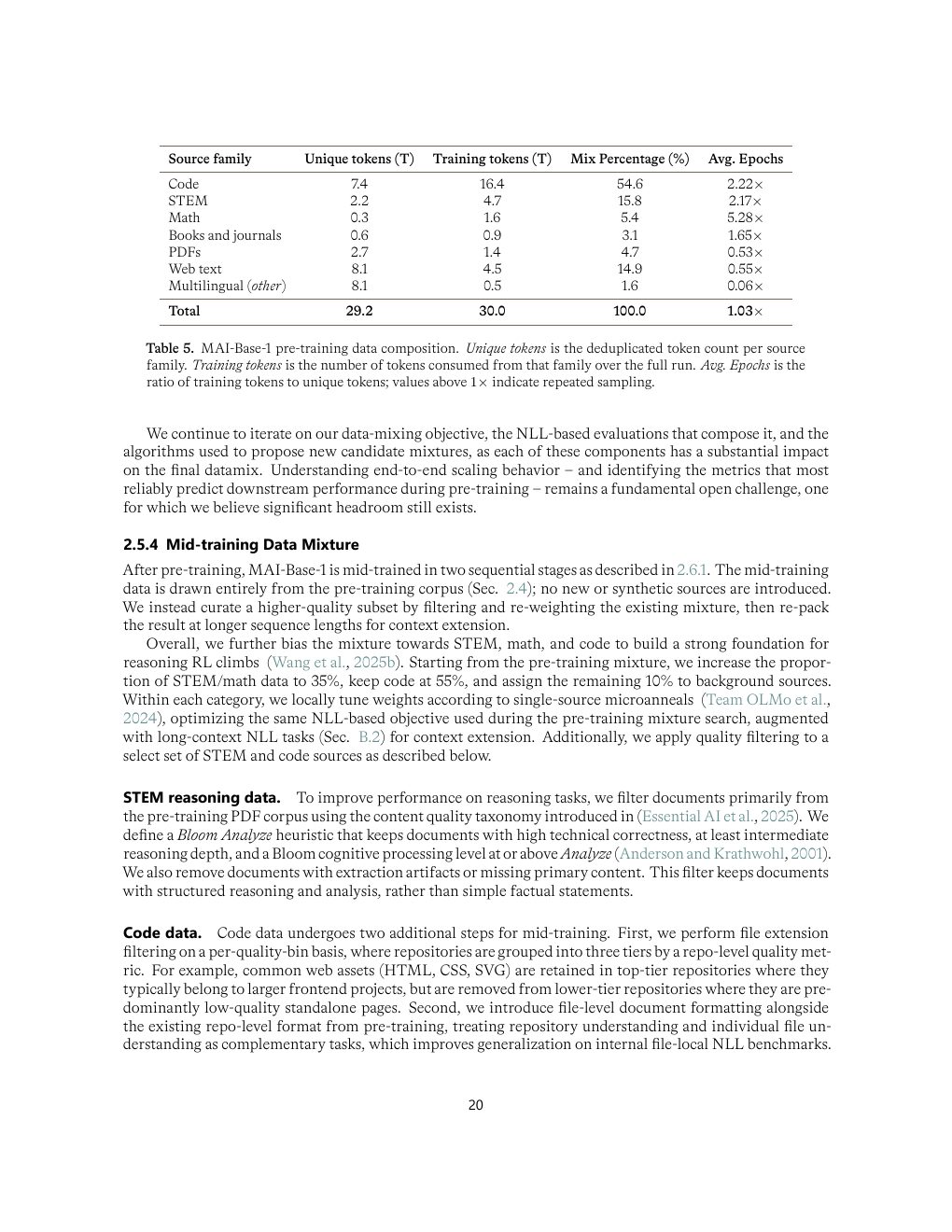
| Table 5 | p.20 | 预训练数据组成与去重 token 数 |
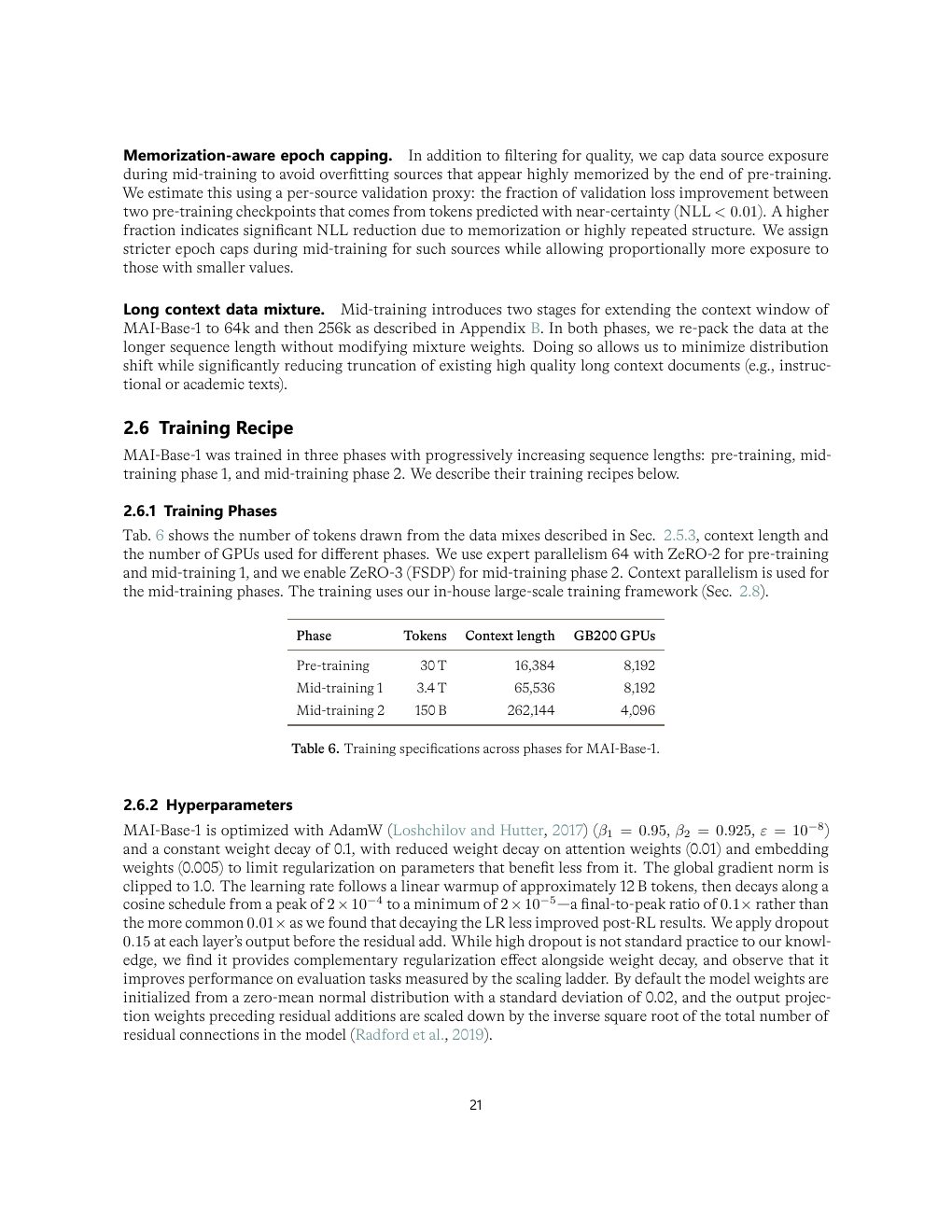
| Table 6 | p.21 | MAI-Base-1 各训练阶段规格 |
| Table 7 | p.29 | 架构开发过程中 v1-v7 演化 |
| Table 8 | p.47 | harmful / borderline prompt 来源 |
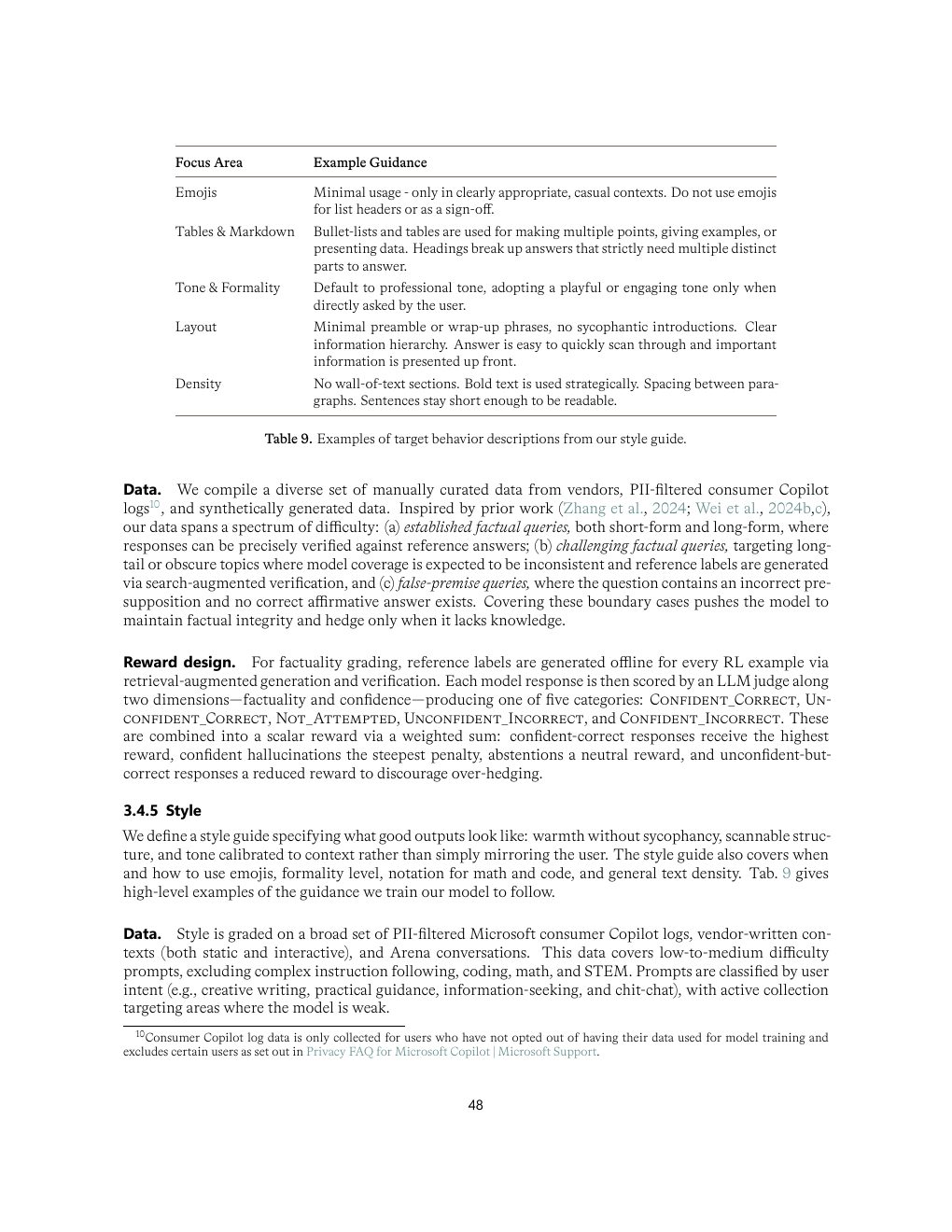
| Table 9 | p.48 | style guide 中目标行为描述示例 |
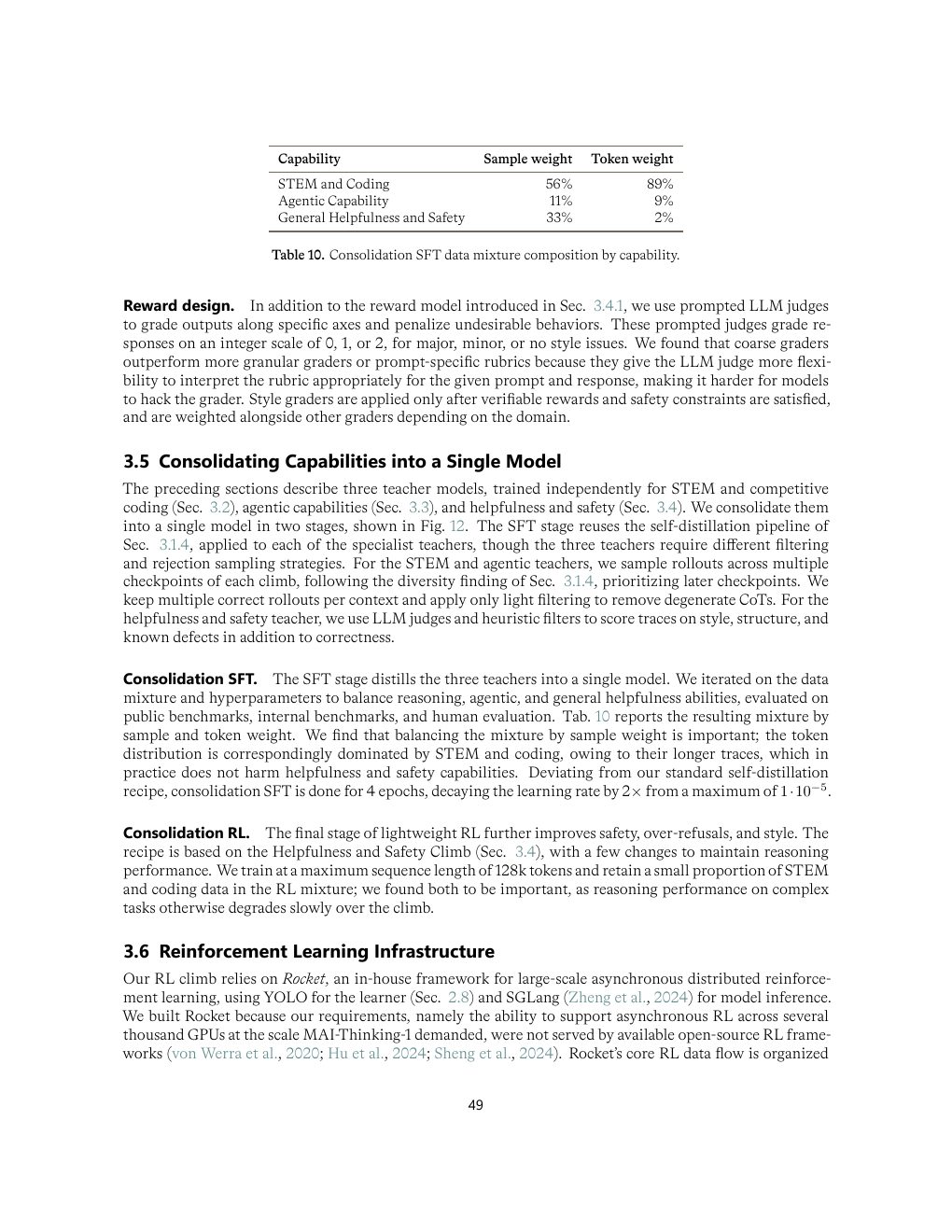
| Table 10 | p.49 | consolidation SFT 数据混合比例 |
| Table 11 | p.53 | STEM 与 agentic coding public benchmark 结果 |
| Table 12 | p.54 | 各类 public benchmark 结果 |
| Table 13 | p.55 | human side-by-side evaluation 任务分布 |
| Table 14 | p.56 | 与 Sonnet 4.6 / Opus 4.6 的人类评测结果 |
| Table 15 | p.98 | instruction following taxonomy 高层约束示例 |
| Table 16 | p.99 | multi-turn IF capabilities 示例 |
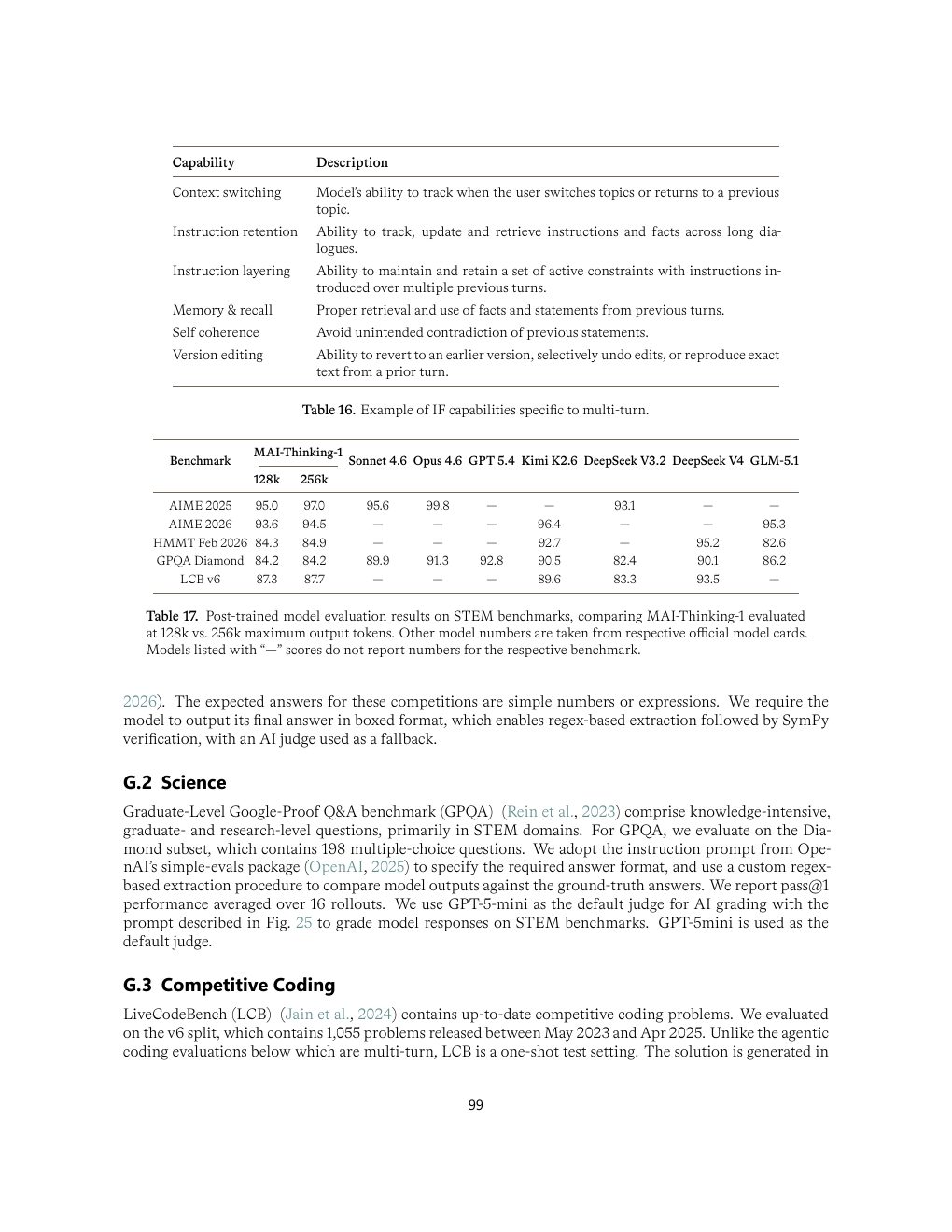
| Table 17 | p.99 | 不同 token budget 下 STEM benchmark 结果 |
| Table 18 | p.102 | user request classification dimensions |
| Table 19 | p.104 | 为什么省略 MRCR benchmark |
| Table 19b | p.105 | Additional Long Context Benchmarks;论文中重复编号 Table 19 |
本地图表证据页


















证据边界与资料索引
本文基于微软官方技术报告《MAI-Thinking-1: Building a Hill-Climbing Machine》与微软官方发布页。报告全文 109 页,含 19 个编号表格和 26 个编号图。由于完整训练数据、内部 benchmark、红队样本、reward model 数据和集群运行日志未公开,本文对这些部分只分析报告披露的机制与边界,不声称可独立复现。
- 官方技术报告 PDF:MAI-Thinking-1: Building a Hill-Climbing Machine
- 官方发布页:Building a hill-climbing machine: Launching seven new MAI models
- 配图说明:首页、架构页、RL 概览页、评测页配图均来自官方技术报告对应页面,仅用于辅助读者定位,不替代原文。