核心判断
MAI-Base-1 的设计不是从论文 novelty 出发,而是从“8K GB200 级别训练和长上下文服务会在哪里死掉”反推出来的。local/global attention 降低长序列 attention 成本,GQA 降低 KV cache,MoE 用稀疏激活换总容量,LatentMoE 降 all-to-all 字节量,dropless routing 避免 token dropping 污染实验结论,zero-init attention output 抑制早期 router imbalance,FP8 recipe 则把低精度只放在能承受的位置。
六条设计轴:每个术语解决一个不同瓶颈
Attention pattern
从 full attention 走向 sliding window、block sparse、periodic global。目标是让长上下文成本近似线性化,但仍保留跨窗口信息通路。
KV sharing
MHA → MQA → GQA。目标不是训练更强,而是 decode 时少写少读 KV cache;GQA 是质量与吞吐之间的中间点。
Sparse capacity
Dense FFN → MoE top-k experts。目标是增加 total parameters 而不让 active FLOPs 同步爆炸。
Routing semantics
capacity factor + token drop → dropless / block sparse dispatch。目标是让训练信号不被系统近似扭曲。
Initialization stability
残差缩放、zero-init、norm placement。目标是在极深、MoE、长序列模型启动阶段不让路由或激活分布先炸。
Numerical recipe
FP32 → FP16/BF16 → FP8 混合精度。目标是提升 GEMM throughput,但保留 router logits、attention scores、residual 等敏感路径。
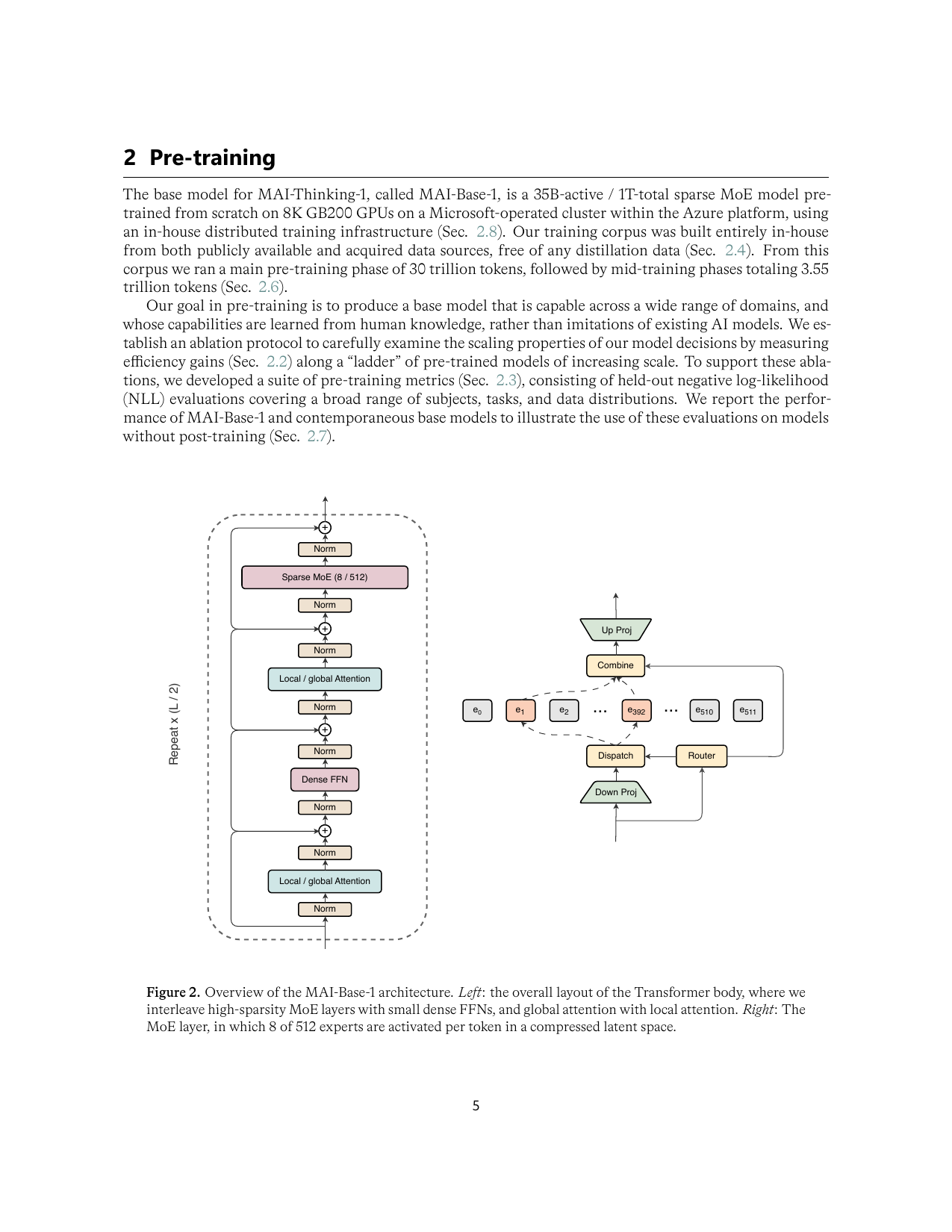
演进轨迹:从算法想法到生产配方
Attention:local/global attention 与 GQA 是两个不同层面的省钱
local/global attention 省的是序列维度上的 attention 计算;GQA 省的是 decode 阶段 KV cache 的内存带宽。它们经常一起出现,但作用点完全不同。
Local / sliding-window attention
每个 token 只看附近窗口,例如 MAI 的 local window 512。训练时 attention matrix 从全局 O(n²) 变成近似 O(nw),推理时 KV cache 的有效访问范围也下降。问题是信息跨窗口传播变慢,所以需要周期性 global layer、dilated pattern、random/global tokens 或层间混合来补。
Global attention
Longformer / BigBird 时代的 global tokens 是少量特殊 token 能看全局;MAI / Gemma 这种 periodic design 是每隔若干层放一次 global attention layer。前者更像任务结构先验,后者更像 decoder-only LLM 的系统预算安排。
| 机制 | 省掉什么 | 牺牲什么 | 代表工作 | MAI 中的用法 |
|---|---|---|---|---|
| Full attention | 不省;任意 token 直接互看 | 长上下文下 FLOPs / memory 二次增长 | Transformer, GPT 系列早期 dense attention | 只在 periodic global layer 中保留 |
| Sliding window / local | attention FLOPs 与 KV 访问 | 跨窗口依赖需要多层传播 | Longformer, Mistral 7B, Gemma 3 | 5 个 local attention 配 1 个 global attention;window 512 |
| Global token / global layer | 比全层 full attention 更便宜地注入全局信息 | global 频率太低会影响长程整合 | Longformer, BigBird, Gemma 3 | 每 6 层中 1 层 global;global layer 不用位置编码以提升效率 |
| MQA | KV cache 几乎降到单 KV head | 质量可能下降;训练/迁移需要小心 | Fast Transformer Decoding: One Write-Head Is All You Need | 没有用最极端 MQA |
| GQA | KV heads 从 attention heads 降到少量 groups | 比 MHA 表达少,比 MQA 质量风险低 | GQA: Training Generalized Multi-Query Transformer Models | 8 KV heads,每头 dim 128 |
MoE:容量扩张不是免费午餐,真正难点是通信、负载和 GEMM shape
MoE 的口号是“更多参数、更少 active compute”,但系统上它把 dense FFN 的大 GEMM 变成了 router、dispatch、all-to-all、小 GEMM、combine 和 load balancing。规模越大,越不是算法问题,而是通信与内存布局问题。
Top-k routing
每个 token 由 router 选 k 个专家。top-1 简单但表达较硬;top-2/top-8 更柔软但通信和 combine 更贵。MAI 选择 top-8 / 512 experts,是高稀疏度与 routing 平滑性的折中。
Dense + MoE 交替
不是每层都 MoE。Dense FFN 提供共享通用变换,MoE 层提供条件容量。MAI 认为 interleaved layout 比 every-layer MoE 更适合 wall-clock 和服务成本。
LatentMoE
先把 hidden 表示降维到 latent space 再 all-to-all,回来后再升维。它不是改变 routing 目标,而是直接减少跨 GPU 搬运的字节数和专家 GEMM 尺寸。
| 阶段 | 核心贡献 | 系统问题 | 后续演化 |
|---|---|---|---|
| Shazeer MoE 2017 | 条件计算:每个样本只激活部分专家 | routing 稳定性、load balancing、分布式训练复杂 | 成为 GShard / Switch 的思想源头 |
| GShard 2020 | 自动 sharding + top-k MoE 大规模化 | capacity factor、token drop、all-to-all shape | 形成大规模 MoE 训练标准范式 |
| Switch Transformer 2021 | top-1 routing 简化 trillion-scale MoE | 简单但可能牺牲专家组合表达 | 工业系统继续探索 top-2/top-k 与 shared experts |
| GLaM 2021 | 展示 MoE 的质量/能耗效率 | 推理服务与工程复杂度仍高 | 稀疏模型从研究走向产品候选 |
| MegaBlocks 2022 | block-sparse kernels 支持 dropless MoE 训练 | 需要把动态 token 数映射到硬件友好的块 | 影响后续 dropless / grouped GEMM 设计 |
| Mixtral / DeepSeek / DBRX 2024 | open-weight 稀疏模型配方变透明 | 长上下文、推理路由、专家并行成本 | shared experts、MLA、fine-grained experts 等路线 |
| MAI-Base-1 2026 | top-8/512 + LatentMoE + dropless + global-batch load balance | 8K GPU 下 all-to-all、router imbalance、static memory | 把 MoE 纳入完整 hill-climbing infra 配方 |
Dropless routing:它解决的不只是“别丢 token”,而是实验语义一致性
早期 MoE 常用 capacity factor:每个专家最多接收固定数量 token,溢出的 token 被 drop 或走 fallback。这样硬件 shape 稳定,但训练语义变了。MAI 强调 dropless,是因为 token dropping 会改变 ablation 结论,特别是比较 load-balancing loss、router 初始化或数据分布时。
Capacity-capped routing
优点是每个 expert 的 tensor shape 更固定,易于静态内存和 kernel 调度。缺点是被 drop 的 token 不再真实经过它选中的专家,训练信号被系统近似污染;drop rate 虽低也可能改变哪个方法看起来更好。
Dropless routing
每个 token 都送到选中的专家,通常需要 variable-size all-to-all、block-sparse computation、grouped GEMM、padding/packing 或多轮 capped dispatch。难点从“是否丢 token”转为“怎么不 OOM、怎么不碎片化、怎么 overlap 通信”。
Zero-init attention output:小初始化技巧背后是 MoE 路由稳定性
MAI 把 attention output RMSNorm gains 初始化为 0。直觉是:训练刚开始时,随机 attention 近似对过去 token 做 causal mean pooling,导致不同行 token 表示高度相关;这些相关表示送进 MoE router,容易让大量 token 挤向少数 experts,造成早期负载失衡。
它和 ReZero / SkipInit 同属“残差启动控制”家族
ReZero、SkipInit、DeepNet 等工作都在处理深层 residual network 初始阶段的梯度与激活稳定。MAI 的特殊之处是目标不是单纯稳定 loss,而是防止 attention contribution 过早破坏 token 表示多样性,进而影响下一层 MoE router。
为什么不是把所有东西都 zero-init
zero-init 是给高风险路径装闸门。attention output 初始贡献被关小,但 FFN、embedding、router 仍能提供训练信号。随着 RMSNorm gain 学起来,attention 捕获的上下文信息再逐步接入。
FP8 precision:真正的配方是“哪里能低精度,哪里绝对不能”
FP8 不是把所有 tensor 都改成 8-bit。E4M3 有更多 mantissa、动态范围较小,适合 forward activations / weights;E5M2 动态范围更大、精度更低,适合 gradient 这类 range 更大的数据。MAI 的 recipe 是 BF16 默认,forward GEMM 用 E4M3,data-gradient 用 E5M2,weight-gradient 用 BF16 compute + FP32 accumulation。
| 路径 | MAI recipe | 原因 | 如果乱降精度的风险 |
|---|---|---|---|
| Forward GEMM | FP8 E4M3 | 更高吞吐,E4M3 精度相对好 | scale 不稳会造成激活误差累计 |
| Data-gradient GEMM | FP8 E5M2 | 梯度动态范围更大,需要更多 exponent | overflow / underflow 影响反传 |
| Weight-gradient | BF16 compute + FP32 accumulation | 权重更新更敏感 | 优化器状态污染,长期训练质量下降 |
| Attention scores / router logits / output logits | FP32 | softmax 前 logits 对小误差敏感 | routing 错误、attention 分布异常、词表 logits 偏移 |
| Residual stream / embedding / RMSNorm / router weights | FP32 或保守精度 | 贯穿全模型的状态通路 | 小误差跨层放大 |
| Delayed scaling | 1024-step amax history | 稳定 FP8 scale,避免每步剧烈波动 | scale 抖动导致数值噪声 |
代表工作与关键词对照
| 主题 | 代表工作 | 技术贡献 | 对 MAI 这类系统的影响 |
|---|---|---|---|
| Transformer baseline | Attention Is All You Need, 2017 | attention + FFN + residual + layer norm 构成通用序列架构 | 所有后续 infra 优化都围绕这套结构削成本 |
| Sparse / local attention | Sparse Transformer, Longformer, BigBird, Mistral 7B, Gemma 3 | 用窗口、块稀疏、global token/layer 降低长序列成本 | MAI 的 5 local + 1 global 属于 periodic local/global 路线 |
| Positional encoding | RoPE / NoPE 相关工作 | RoPE 成为 local layer 常用位置编码;部分 global layer 可不用显式 position encoding | MAI local layer 用 RoPE,global layer 不用 position encoding |
| KV cache reduction | MQA, GQA | 减少 decode KV heads,从带宽和显存角度加速服务 | MAI 用 8 KV heads 取得质量/吞吐折中 |
| MoE scaling | GShard, Switch Transformer, GLaM, Mixtral, DeepSeek-V2/V3 | 用稀疏激活扩 total parameters,不线性增加 active compute | MAI top-8/512 + dense/MoE interleaving 是同一演进线的工业配方 |
| Dropless MoE systems | MegaBlocks, Tutel, DeepSpeed-MoE, Megatron-Core MoE | 处理动态 routing、block-sparse compute、expert parallelism、all-to-all overlap | MAI 的 dropless + static-memory mode 是对实验语义和生产内存上界的折中 |
| Initialization stability | ReZero, SkipInit, DeepNet, µParam / norm placement 相关工作 | 控制深层 residual network 初始阶段的激活与梯度 | MAI 把它具体化为 attention output zero-init 以保护 MoE router |
| FP8 training | FP8 Formats for Deep Learning, NVIDIA Transformer Engine, H100/Hopper FP8 | E4M3/E5M2、delayed scaling、mixed precision kernel stack | MAI 的数值 recipe 说明哪些路径可 FP8,哪些必须 FP32 |
关键结论:这些设计不是 isolated tricks,而是同一套预算表
- Attention 省的是序列预算。local/global pattern 让长上下文训练和推理不被 full attention 的二次成本拖死。
- GQA 省的是服务预算。decode 阶段的瓶颈常是 KV cache 带宽和显存,不只是 FLOPs。
- MoE 买的是容量,但付款方式是通信。top-k、expert 数、shared/dense layer、LatentMoE 都是在容量、all-to-all 和 GEMM 效率之间折中。
- Dropless routing 买的是实验可信度。不 drop token 可以避免系统近似改变 ablation 结论,但要付出 variable-size 通信和 static-memory 复杂度。
- Zero-init 说明 optimizer 稳定性和系统负载不是两件事。attention 初始表示塌缩会传导到 router imbalance,再传导到 all-to-all 和 OOM。
- FP8 的核心是边界意识。真正的高质量低精度训练不是全量压缩,而是把 logits、router、residual、optimizer state 这些敏感路径保住。
证据边界与资料索引
本文以 MAI-Thinking-1 官方技术报告为触发材料,并结合公开论文标题、摘要、经典系统路线与 MAI 报告中的架构章节做技术谱系整理。未声称复现实验结果,也不推断未公开的微软内部 kernel、数据或集群配置。
- MAI-Thinking-1: Building a Hill-Climbing Machine — 主要触发材料;关注 2.1、2.6、2.8、Appendix K。
- Longformer: The Long-Document Transformer — local + global attention 的代表工作。
- Big Bird: Transformers for Longer Sequences — sparse/global/random attention 的理论与长序列路线。
- Fast Transformer Decoding: One Write-Head is All You Need — Multi-Query Attention。
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints — Grouped-Query Attention。
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding — 大规模 MoE / sharding。
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity — top-1 MoE 简化路线。
- GLaM: Efficient Scaling of Language Models with Mixture-of-Experts — 稀疏模型效率证据。
- MegaBlocks: Efficient Sparse Training with Mixture-of-Experts — dropless / block-sparse MoE 系统代表。
- Mixtral of Experts — open-weight SMoE 代表。
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model — 经济型 MoE 与长上下文系统设计。
- FP8 Formats for Deep Learning — E4M3/E5M2 格式与 FP8 训练动机。
- Mistral 7B — sliding window attention 与 GQA 的高效 decoder 例子。