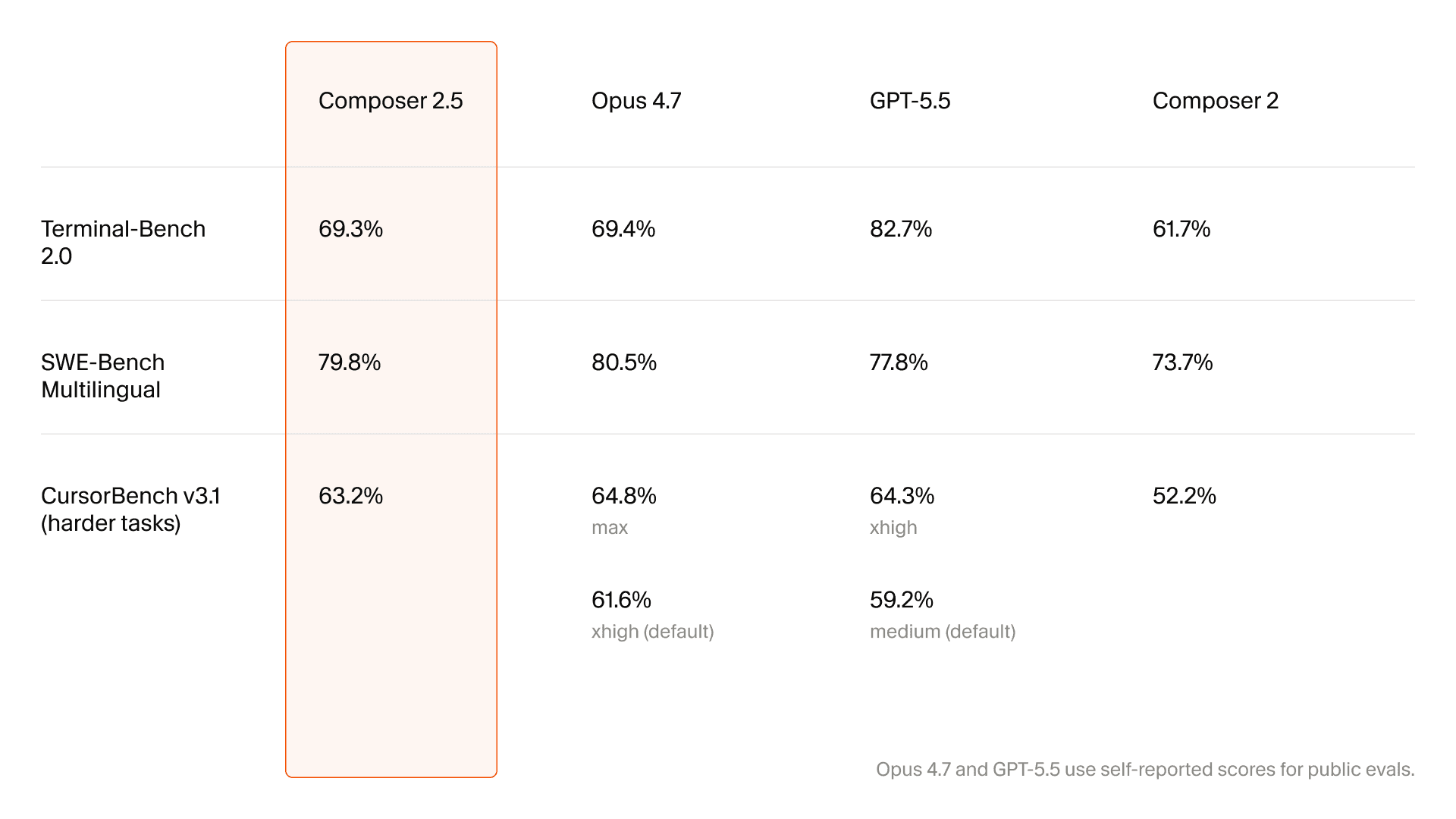
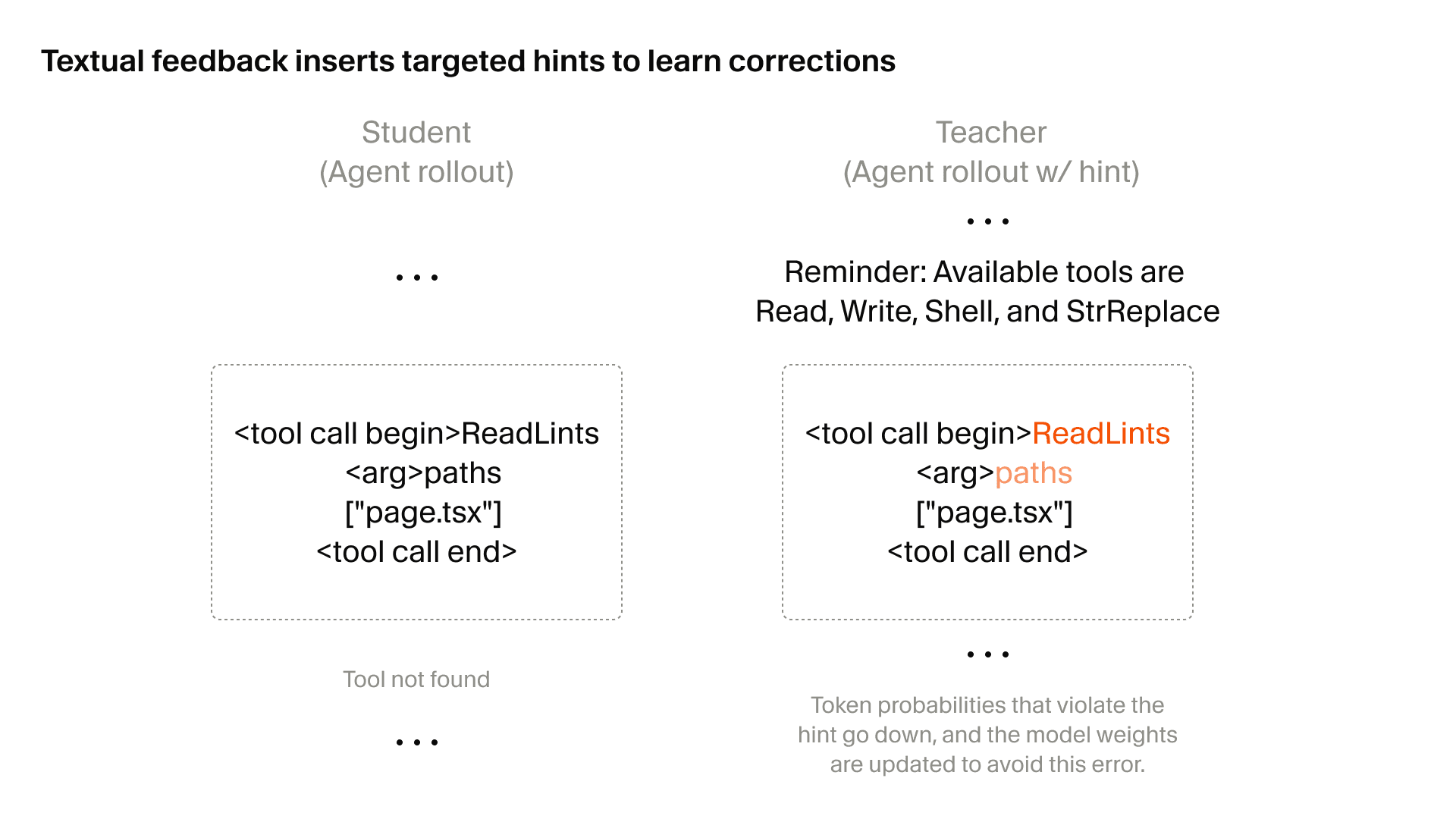
Elie 的判断可以拆成两个观察。
第一,2-3 周 release window 很短。如果 RL 几天后才开始,而公开发布只剩 2-3 周,那么后训练阶段不会是一个从零塑造 coding agent 的超长周期。它可能仍然消耗巨大算力,但从训练策略上看,许多能力需要在更早阶段准备好。
第二,Cursor 数据在 post-training 前加入。Elon 的说法使用了 “supplementary training”,并在另一条更新里直接补充 “others call this mid-training”。这意味着 Cursor 数据不是只用于最后的 RL 奖励或偏好微调,而可能已经进入了 foundation model 之后、SFT/RL 之前的继续训练阶段。
核心翻译:Elie 不是在说 “RL 没用”,而是在提醒:如果一个 1.5T 模型的 coding 提升主要被预期发生在短 release window 内,那就要看它在 RL 前是否已经拥有足够强的 code-shaped prior。Cursor 数据和 mid-training 可能才是这轮能力跃迁的主要资产。
Elon 回复称 Grok V9 1.5T run 看起来很好,而且这是在 Cursor 数据加入 supplemental training 之前。
Elon 称 1.5T V9 刚完成训练,下一步加入 Cursor 数据做 supplemental training,别人称之为 mid-training,然后 SFT 和 RL,大约 3-4 周发布。
Elon 称 Grok foundation model V9-Medium 1.5T 完成训练,已加入大量 Cursor 数据且后续还有更多;fine-tuning underway,RL 几天后开始,2-3 周公开发布,尤其会改进 difficult coding tasks。
Elie 把这三段信息合起来解读:短 RL 窗口 + Cursor 数据前置加入,指向类似 Composer 2.5 的 heavy mid-training 与 code focus。