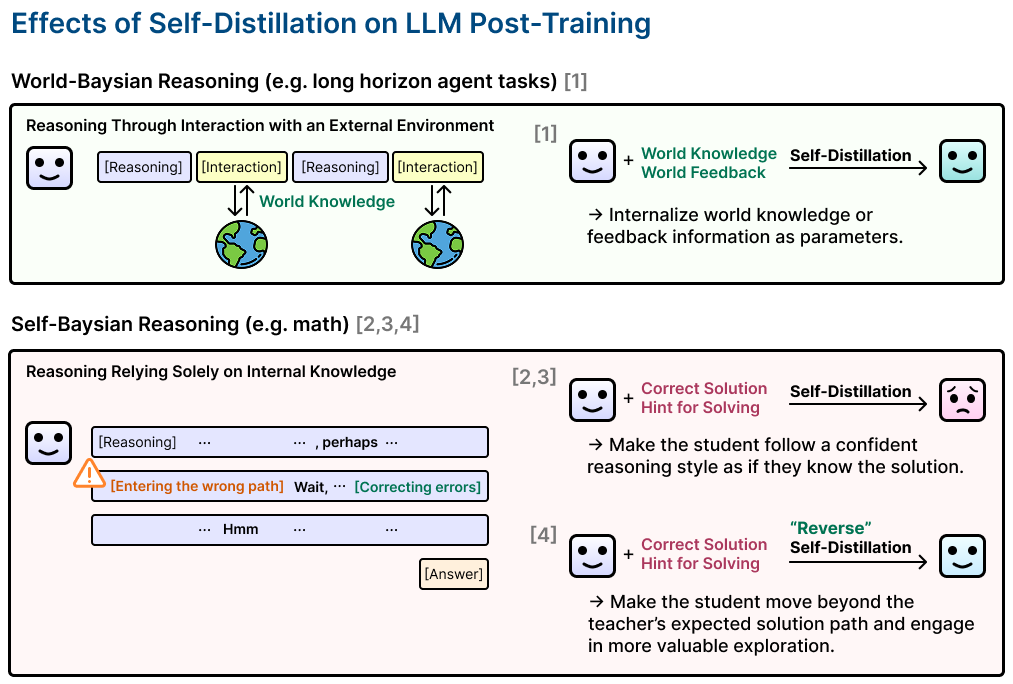
作者 Jeonghye Kim 把 MSRA 实习期间围绕 self-distillation 与 exploration 的四篇工作,压缩成一个更 general 的判断:同一种训练技术,在不同推理反馈结构里可能方向相反。agent 长程任务有环境状态、失败反馈和奖励,自蒸馏能把外部世界经验内化进参数;数学和纯符号推理没有即时环境反馈,模型很大程度上依赖自己说出的“wait / perhaps / hmm”来触发回看、换路和纠错。
一句话判断:如果错误检测来自外部世界,自蒸馏常常是在压缩经验;如果错误检测只能来自模型内部的不确定性外显,自蒸馏可能是在删除推理系统的刹车。
所以,这不是“长 CoT vs 短 CoT”的审美问题,也不是“teacher trace 更干净所以更好”的工程常识问题。真正的问题是:teacher 的轨迹为什么看起来更干净?是因为它吸收了可验证的外部反馈,还是因为它已经知道答案,因此不再需要真实求解者会经历的怀疑和检查?