base model 的 hidden states 是后续 instruction tuning、RL、RAG embedding、classification probe、tool state 表征等能力的底座。如果预训练只让 logits 好看,hidden geometry 未必对迁移最友好。
X Thread · ICML 2026 Poster · Pre-training Objective
NITP:把“预测下一个 token”推进到表示空间
aHpaBean 的 X 预告和 NITP 公开仓库指向一个非常具体的问题:NTP 只在最终 logits 上用 one-hot token 施压,可能没有充分约束 hidden state 的几何结构。NITP 的想法不是替换 NTP,而是在同一个自回归训练里增加一条“预测下一个 token 的浅层上下文化表示”的辅助目标。
NTP 的盲点:它监督“答案”,但不直接监督“表示形状”
标准 next-token prediction(NTP)训练目标很强,但它的信号最终落在 vocabulary logits 和交叉熵上。换句话说,训练会强迫模型让正确 token 的概率变高,却不直接规定最后 hidden state 应该以什么几何结构组织语义。
把问题写成训练链路会更清楚
对位置 \(t\),Transformer 得到最后层 hidden state \(h_t^{L}\),LM head 把它映射到 vocabulary logits:
\[
z_t = W_{\mathrm{lm}} h_t^{L}, \qquad
\mathcal{L}_{\mathrm{NTP}} =
-\log p(x_{t+1}\mid x_{\le t})
\]
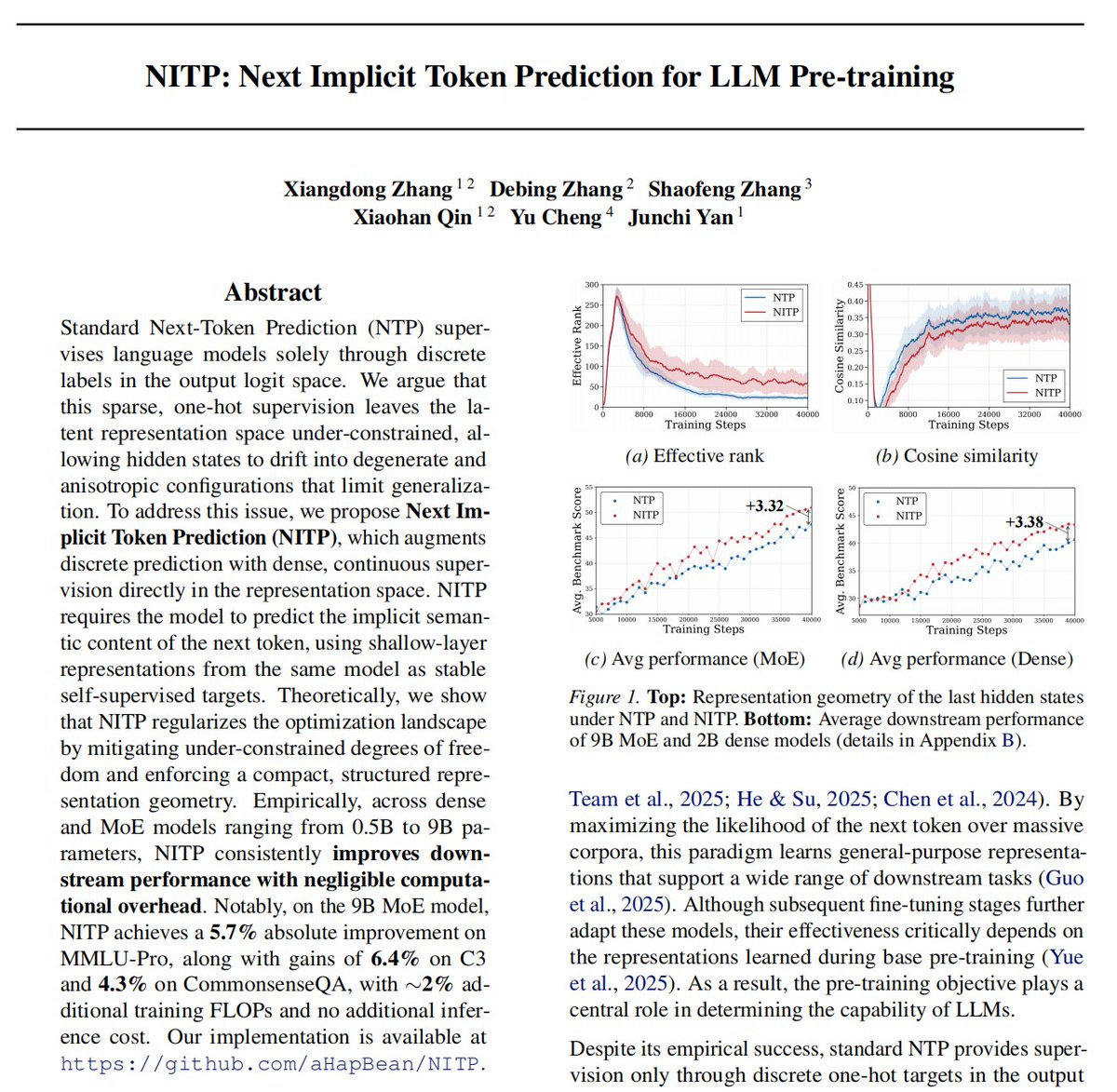
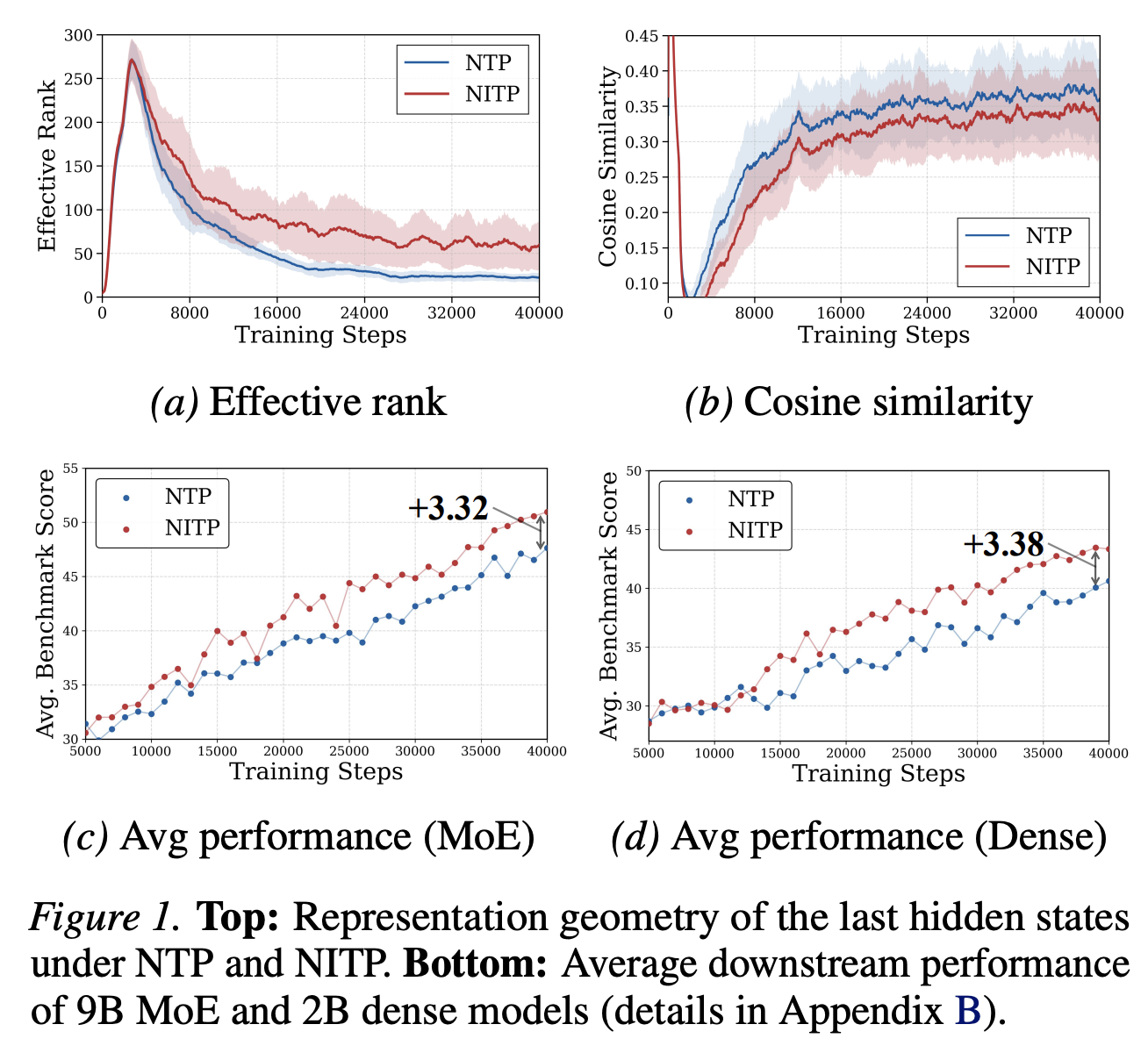
这里的监督对象是 \(x_{t+1}\) 的离散 token id。隐藏状态只通过 \(W_{\mathrm{lm}}\) 和 softmax CE 间接受到梯度。因此,只要最终 logits 能把正确 token 排上去,hidden state 中仍可能有大量自由度没有被约束。NITP 作者把这个问题描述为 latent representation space under-constrained,并进一步关联到 hidden states 的 degenerate / anisotropic configurations。
从公开图表看,作者主要用 effective rank 和 cosine similarity 描述:有效秩低、过度 cosine alignment 高,意味着表示维度没有充分展开,样本 hidden states 可能挤到相似方向上。
NITP 没有说 CE 不需要。它保留 \(\mathcal{L}_{\mathrm{NTP}}\),只是承认 token identity 和 representation geometry 是两个不同训练对象。
方法机制:预测下一个 token 的“隐式表示”
NITP 的实现从 README 看非常简洁:在标准 NTP 之外,加一个 cosine alignment loss。目标不是下一个 token 的 one-hot id,也不是 teacher logits,而是同一个模型浅层对下一个 token 形成的上下文化表示。
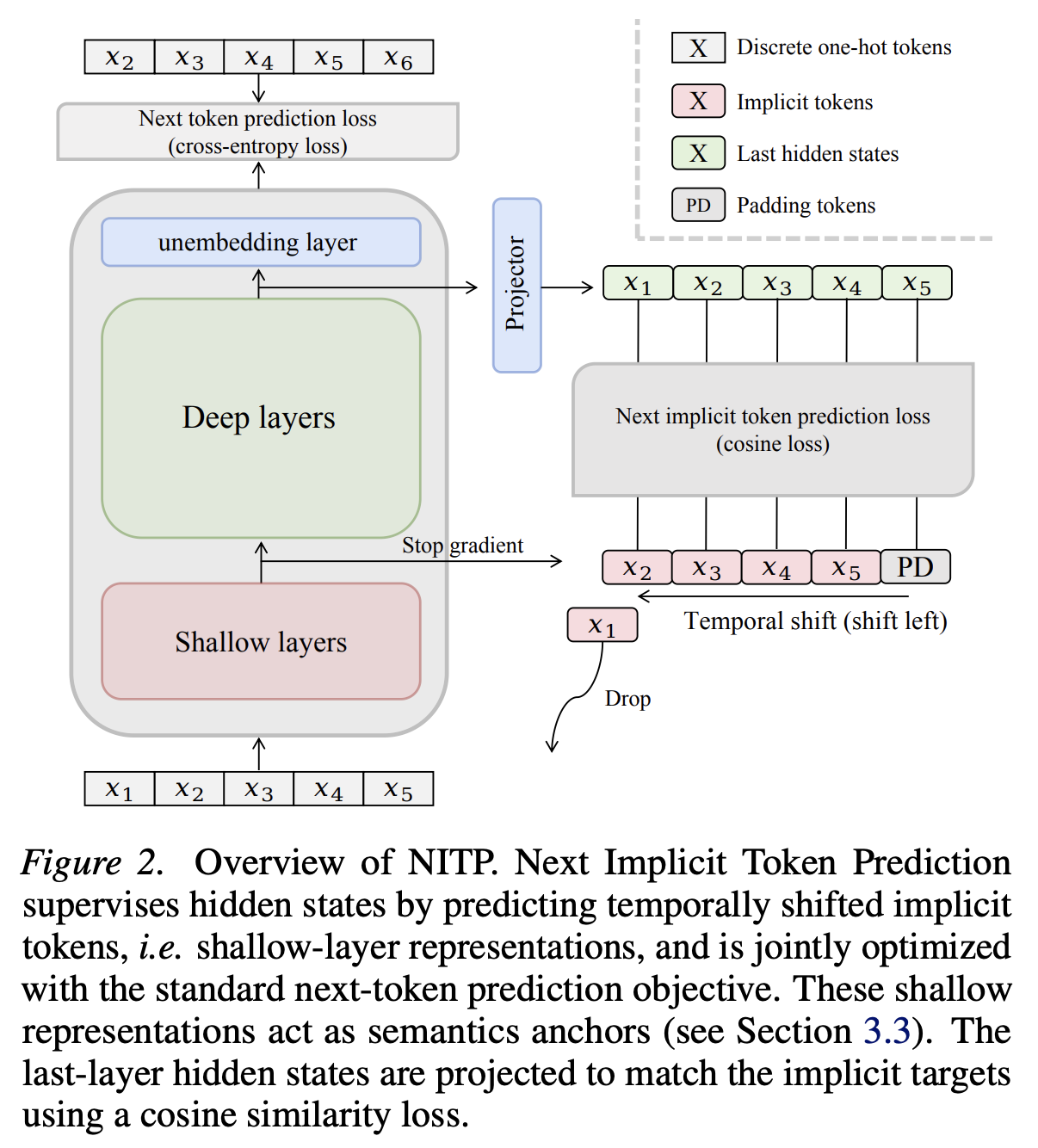
逐步拆开
- 正常自回归输入。给模型输入 \(x_{\le t}\),标准 CE 仍然预测离散 token \(x_{t+1}\)。
- 取当前位置最后层表示。拿到位置 \(t\) 的最后层 hidden state \(h_t^{L}\)。
- 取下一位置浅层目标。同一次 forward pass 里,拿到 token \(t+1\) 在浅层 \(s\) 的 contextual representation \(h_{t+1}^{s}\),并 stop-gradient。
- 投影后做 cosine alignment。用训练时 projection head \(g(\cdot)\) 把 \(h_t^{L}\) 映射到目标空间,对齐 \(h_{t+1}^{s}\)。
- 总 loss 相加。NTP 继续负责 token likelihood,NITP 负责表示空间的密集连续监督。
\[
\mathcal{L}_{\mathrm{total}}
=
\mathcal{L}_{\mathrm{NTP}}
+
\lambda \mathcal{L}_{\mathrm{NITP}},
\qquad
\mathcal{L}_{\mathrm{NITP}}
=
1 -
\cos\left(g(h_t^{L}),\ \mathrm{sg}(h_{t+1}^{s})\right)
\]
上式里的 \(\mathrm{sg}\) 表示 stop-gradient。它让浅层 target 在这个辅助损失里只作为目标,不被这条 loss 反向推着一起移动,避免 teacher-target 自身被同一目标牵引导致训练信号不稳定。
为什么叫 implicit token?不是把 token id 换个名字,而是把“下一个 token 在当前上下文中由浅层网络形成的连续表示”当成目标。它比 one-hot id 更密集,因为一个向量会携带句法、语义、上下文位置和局部组合信息;它又比外部 teacher 更轻,因为目标来自同一个模型的同一次 forward pass。
README 强调 implicit targets 来自同一次 forward pass,不需要外部 encoder、额外数据或额外 backbone forward pass。新增成本主要来自 projection head 和 cosine loss。公开页面声称 9B MoE 设置训练 FLOPs overhead 约 2.3%,5k-step wall-clock overhead 约 1.8%。
projection head 只服务训练目标;预训练结束后丢弃。推理时模型仍然是标准 causal LM:输入上下文,输出 next-token logits。NITP 改变的是训练出来的 hidden geometry,不改变推理接口。
证据:公开结果支持什么,不支持什么
当前最可靠的结果来自 ICML 摘要与 GitHub README 图表。由于论文 PDF 和代码尚未公开,应该把这些结果理解为作者公开 claim,而不是已完成独立复现实验。
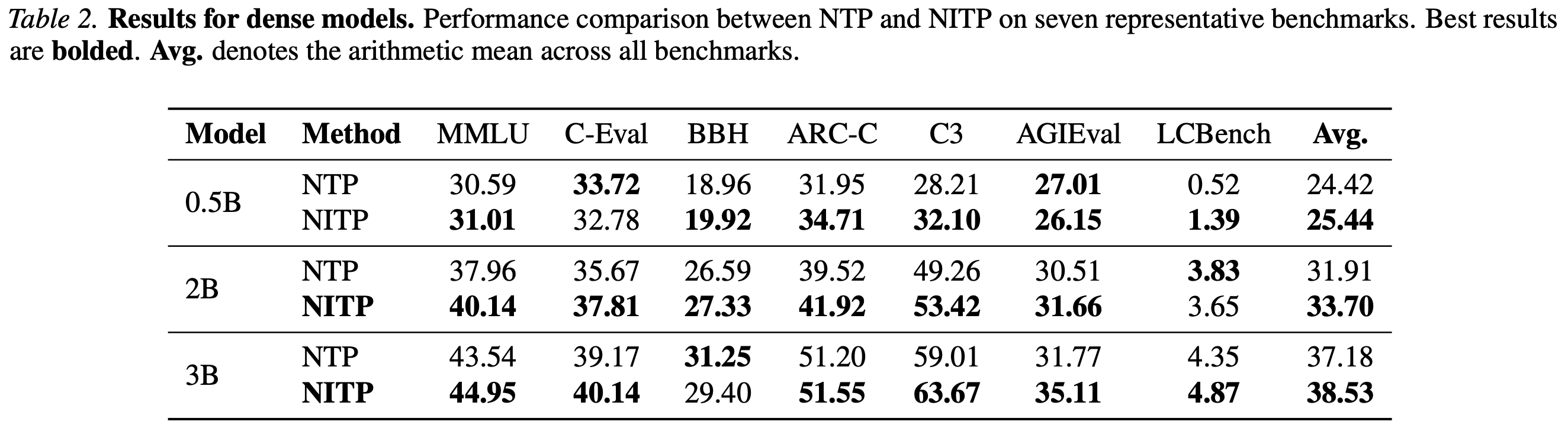
| 证据对象 | 公开 claim | 它实际说明什么 | 仍缺什么 |
|---|---|---|---|
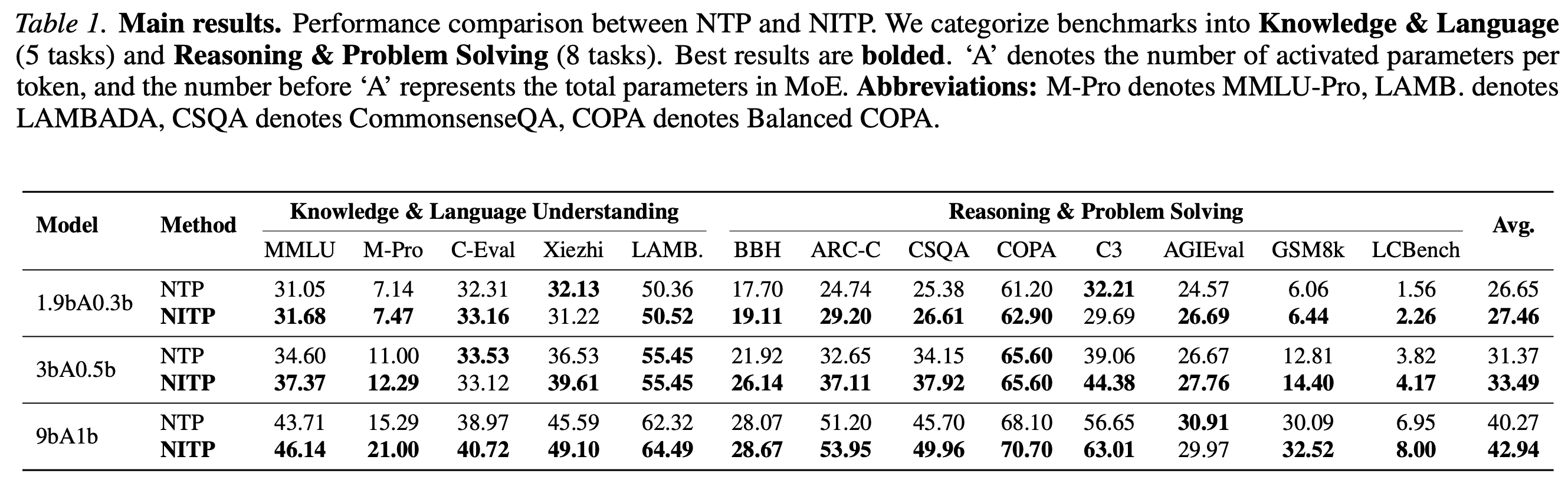
| 9B-A1B MoE 主结果 | Avg 从 40.27 到 42.94;MMLU-Pro +5.7,C3 +6.4,CommonsenseQA +4.3。 | 如果实验设置匹配,这说明 representation loss 能带来非平凡下游增益,而不是只在 embedding probe 上好看。 | 缺完整训练配方、数据、token 数、随机种子、超参扫描与统计方差。 |
| Dense 模型 | 0.5B/2B/3B dense model 平均分均有提升。 | 方法不依赖 MoE routing;更像 objective-level 改动。 | 缺更大 dense 模型、长训练曲线和 scaling law 式分析。 |
| MTEB frozen probe | 3B MoE frozen mean-pooled last-layer representation,25 个英文 MTEB 任务 overall +2.32,23/25 任务改善。 | 这是报告中最贴近“表示质量改善”的证据,因为它冻结模型,不靠下游 fine-tuning 修正表示。 | 缺任务列表、每任务方差、pooling 方案敏感性,以及和专门 embedding training 的差距。 |
| 效率 | 9B MoE training FLOPs overhead 约 2.3%,wall-clock overhead 约 1.8%,推理 overhead 为 0。 | 如果成立,NITP 是一个低侵入辅助目标,适合塞进已有 pre-training loop。 | 缺不同硬件、batch size、sequence length、activation checkpointing 设置下的 overhead。 |
和 JEPA、distillation、CCE 的边界
回复区最有价值的地方,是把 NITP 放进更大的方法谱系里。表面上它像 JEPA,因为都预测 representation;也像 distillation,因为都有 hidden/logit target;还会让人问 CCE 是否兼容。关键差别在训练范式、target 来源和损失对象。
| 方法 | 训练对象 | target 是什么 | 和 NITP 的关系 |
|---|---|---|---|
| 标准 NTP | 自回归语言模型 | 下一个 token 的 one-hot / CE 标签 | NITP 保留它作为主目标;NITP 不是替代 NTP,而是补一条 representation loss。 |
| JEPA / I-JEPA | 通常是 masked context 到 target representation 的自监督学习 | target block / masked position 的 latent representation | 相似点是 representation-space prediction;作者回复指出差别在 NITP 是 autoregressive LM setting,用 temporally shifted implicit token representation alongside NTP,而不是 JEPA 式 masked prediction。 |
| Self-Distillation-MTP / future-token distillation | 语言模型训练中的多 token 或分布匹配 | future-token logits、probabilities 或 teacher distribution | 作者承认 related flavor,但强调 NITP motivation 更偏 representation geometry,监督直接发生在 hidden/representation space,而不是 future-token logits/distributions。 |
| Cut Cross-Entropy (CCE) | 大词表语言模型 CE 计算优化 | 仍是标准 token-level CE,只是避免 materializing full-vocab logits | CCE 可用于 NITP 的 NTP loss 部分;NITP 的额外 objective 在 hidden space,和 CCE 优化的 CE 计算路径分离。 |
JEPA 的核心是从 context 预测被 mask 或目标区域的 latent representation,重点常在非自回归/掩码式表示学习。NITP 的 target 是时间右移的下一 token 表示,并且 CE 仍然存在。这会让它更适合直接嵌入 LLM pre-training,而不是另起一个 representation encoder 训练范式。
logit distillation 的对象是 output distribution;hidden-state distillation 常需要 teacher 或缓存 teacher hidden。NITP 的 target 来自同一模型浅层,是 online self-supervised target。它想修的是 representation geometry,而不只是让 student 模仿 teacher 的输出偏好。
和 Cut Cross-Entropy 的关系容易误读。CCE 解决的是大词表 CE 计算的内存问题:不显式 materialize 全 token × vocab logits 矩阵,而是在 kernel 中计算正确 token logit 与 log-sum-exp。它不改变训练目标。NITP 改变训练目标,但保留 CE。因此二者可以互补:CCE 优化 \(\mathcal{L}_{\mathrm{NTP}}\) 的计算,NITP 增加 \(\mathcal{L}_{\mathrm{NITP}}\)。
可能的失败模式
NITP 的概念很干净,但真正难点在 target 层选择、loss 权重、representation collapse 诊断和大规模训练稳定性。下面这些是读公开材料后最需要继续核验的点。
README 说 shallow-layer contextual representation 是 stable self-supervised targets。但浅层表示也在训练中变化,且不同层携带的词法/句法/语义比例不同。选太浅可能目标过局部,选太深可能和 final hidden 太耦合。
辅助 loss 太小可能没有几何约束,太大可能干扰 CE 的 token discrimination。当前公开材料没有展示权重扫参、不同模型规模下的最佳区间和训练早晚期动态调度。
目标是降低异常 anisotropy,但 cosine loss 本身也会鼓励方向对齐。如果 target 分布或 normalization 处理不好,可能把另一种方向偏置注入 hidden space。
公开 claim 说 overhead 很小,但 NITP 仍增加了训练计算。严谨比较需要 matched FLOPs、matched wall-clock、matched tokens 三种口径,分别回答不同问题。
表示更好不必然等于生成概率更校准。需要看 perplexity、ECE、长文本 generation、instruction tuning 后表现,以及 safety/alignment 阶段是否放大或抵消收益。
当前仓库写着 implementation code coming soon。没有代码时,很难判断 activation hook、stop-gradient、distributed training、MoE routing 和 projection head 的工程细节。
如果要复现,最小工程草图是什么
这不是论文复现代码,而是根据公开 README 推出的最小训练结构。真正实现时要等官方代码确认层索引、normalization、projection head 结构、loss mask 和超参。
# inputs: token ids [B, T]
# model returns all hidden states when output_hidden_states=True
outputs = model(input_ids, output_hidden_states=True)
final_h = outputs.hidden_states[-1] # [B, T, D]
shallow_h = outputs.hidden_states[s] # [B, T, D_s]
logits = outputs.logits # [B, T, V]
# Standard next-token prediction
ntp_loss = cross_entropy(
logits[:, :-1, :].reshape(-1, vocab_size),
input_ids[:, 1:].reshape(-1),
)
# Next implicit token prediction
pred = projection_head(final_h[:, :-1, :]) # predict representation for t+1
target = shallow_h[:, 1:, :].detach() # stop-gradient target
nitp_loss = 1.0 - cosine_similarity(pred, target, dim=-1)
nitp_loss = nitp_loss[loss_mask[:, 1:]].mean()
loss = ntp_loss + lambda_nitp * nitp_loss实现上最容易出错的地方是 shift。NITP 不是让 \(h_t\) 重构自己,也不是让 \(h_{t+1}\) 预测 \(h_{t+1}\)。它的核心是 temporally shifted target:当前位置最终表示预测下一个 token 的浅层表示。这个 shift 如果写错,方法语义会直接变掉。
Insight:NITP 真正值得关注的地方
我对 NITP 的判断是:它值得关注,不是因为“next-token prediction 已死”,而是因为它指出了一个更精确的预训练目标设计方向:未来的大模型 objective 可能会拆成多个互补监督面,而不是把所有能力都压在 final logits 的 CE 上。
这件事的深层意义
NTP 的成功让很多人默认“只要预测下一个 token,表示自然会好”。NITP 反过来说:预测 token identity 和学到好的 hidden geometry 是相关但不等价的事情。CE 是一个非常强的行为目标,但它对 representation space 的许多自由度只提供间接约束;当模型规模、训练数据和后训练链路变复杂,这些自由度可能决定迁移、检索、推理、长上下文和后续 alignment 的上限。
NITP 的设计克制之处在于,它没有引入外部 teacher,没有改变 LM 推理接口,也没有把 LLM 训练改造成完全不同的 masked representation learning。它只是把“下一个 token”从一个离散 id 扩展成两个对象:一个是 vocabulary 中的 token identity,另一个是模型内部形成的 contextual latent token。这是一个很自然但容易被忽视的拆分。
如果官方代码与论文细节公开后结果站得住,NITP 可能成为低成本 pre-training regularizer:不改变数据、不改变 tokenizer、不改变推理路径,只增加一个表示层辅助目标。
它更大的启发是 objective decomposition:把 CE、representation geometry、long-horizon state、tool observation、retrieval embedding 等训练信号拆开设计,而不是期待一个 token CE 自动学会所有内部结构。
最终结论:NITP 当前还不是一个可完全复现的开源训练 recipe,因为论文和代码还未释放;但从公开摘要、README 和作者回复看,它提出的问题非常具体,机制也足够简洁。最该继续追踪的不是“它是不是 JEPA 改名”,而是它能否在 matched-budget、长训练、后训练和真实生成质量上持续证明:更好的 representation geometry 会转化成更稳的语言模型能力。
证据边界与资料索引
本文区分三层证据:一是 X 原帖和作者回复,二是 NITP GitHub/ICML 页面,三是讨论中被拿来比较的 JEPA、Self-Distillation-MTP、Cut Cross-Entropy 等相关材料。由于 NITP 的论文 PDF、正式引用和实现代码在写作时尚未公开,本文只分析公开材料能支持的机制,不虚构论文正文细节。
X 原帖发布时间为 2026-05-23,作者称 NITP 将发布,并给出定位:一种超越 next-token prediction 的 LLM 预训练范式,通过学习 next token 的 implicit representation 修复 representation degeneration。回复区进一步说明:目标是 temporally shifted target;监督直接在 hidden/representation space;可与 CCE 的标准 CE 优化并存。
X threadauthor repliesmedia OCRGitHub README 写明题名、作者、ICML 2026、方法公式、结果图、MTEB 线性 probe 与效率;ICML poster 页面给出摘要和关键性能 claim。当前代码仍标注 coming soon,论文 PDF 与 citation 尚未公开。
GitHub READMEICML posterassets
2026-05-23 10:46 UTC:主帖
NITP 被描述为新的 LLM pre-training paradigm,核心短语是 “learning the next token's implicit representation”。
2026-05-23 14:50-15:03 UTC:作者回复
作者确认 temporally shifted target,区分 JEPA 的 masked prediction,区分 future-token logits/distributions,说明 CCE 可用于 NTP loss 而 NITP loss 独立存在。
公开仓库与 ICML 页面
仓库 README 和 ICML poster 页面补齐了方法、效果和效率声明,但代码、论文 PDF、citation 尚未公开。