传统实验范式的问题
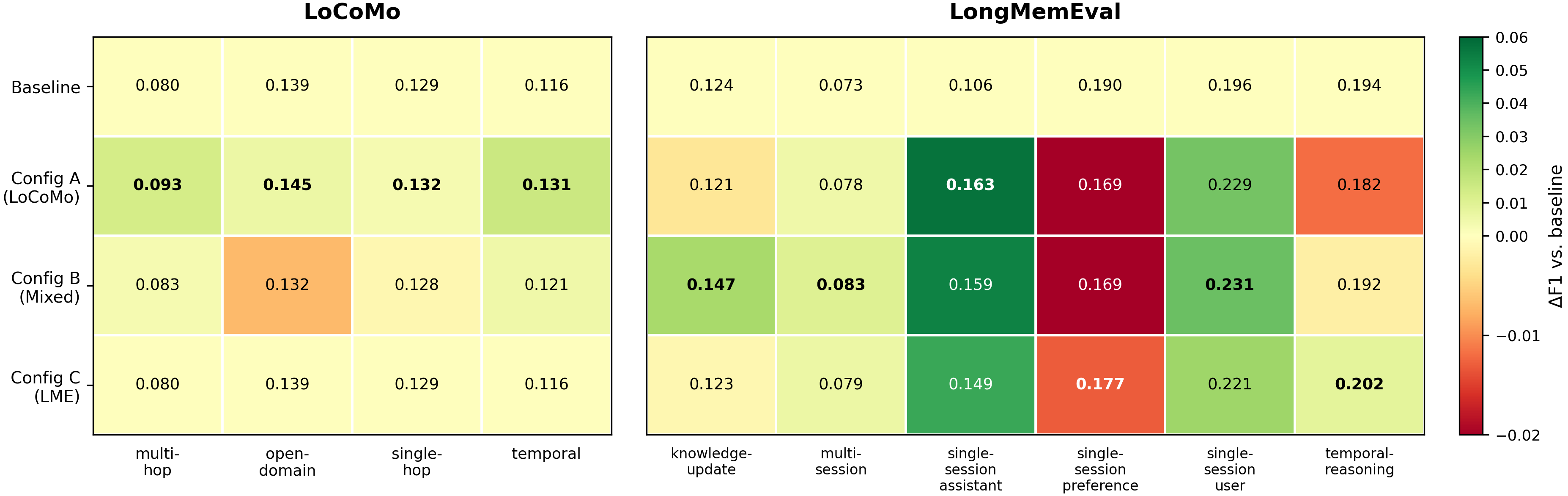
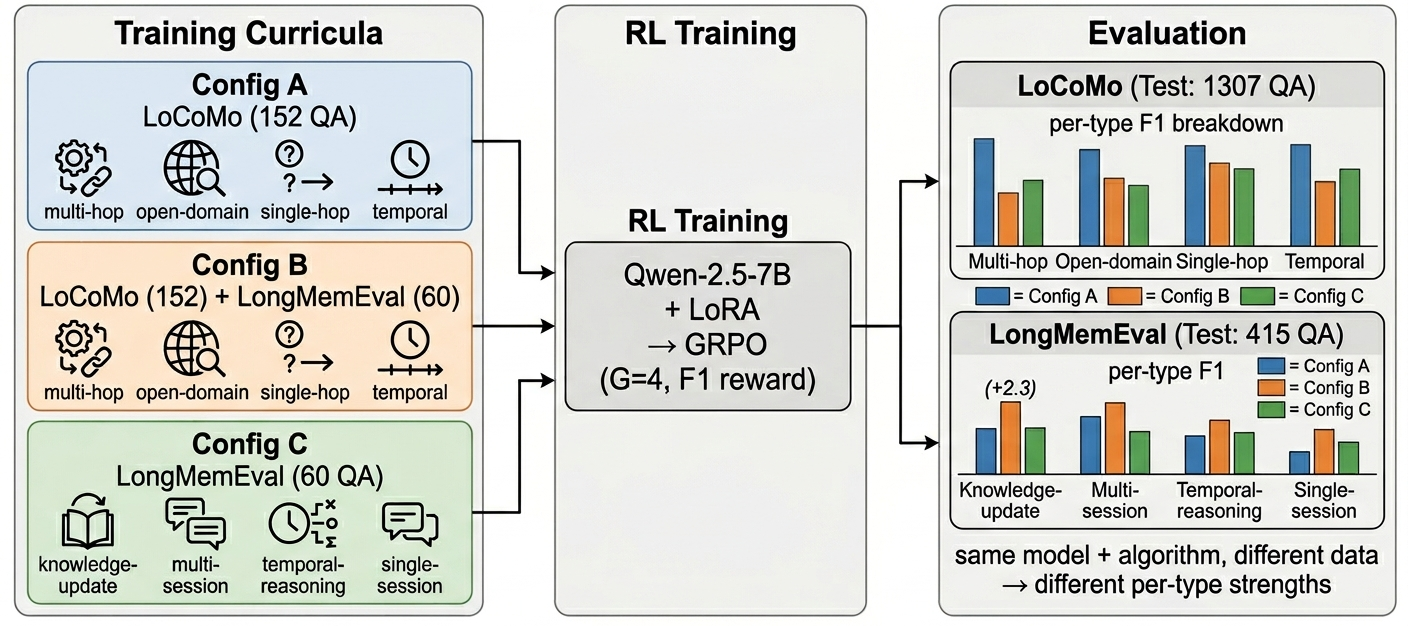
现有 RL-for-memory-agent 工作通常在一个 benchmark 上训练,然后报告一个 aggregate score。 但 memory-augmented QA 并不是一个单技能任务:single-hop、multi-hop、temporal reasoning、knowledge-update 需要的检索和推理模式不同。
如果只看整体 F1,研究者可能会得出“某个 recipe 稍微更好”的结论,却看不到模型实际上只是在某些问题类型上被训练数据推了一把,在另一些类型上没有提升甚至退步。