一句话结论
这篇论文把 LLM post-training 从“只更新参数”改成“两条学习通道共同演化”:慢通道更新模型权重 theta,快通道更新文本上下文 / prompt population Phi。它的思想很自然:不是所有任务经验都应该永久写进权重;有些经验更像临时策略、错误检查表、任务格式偏好,放在可快速改写的上下文里更合适。
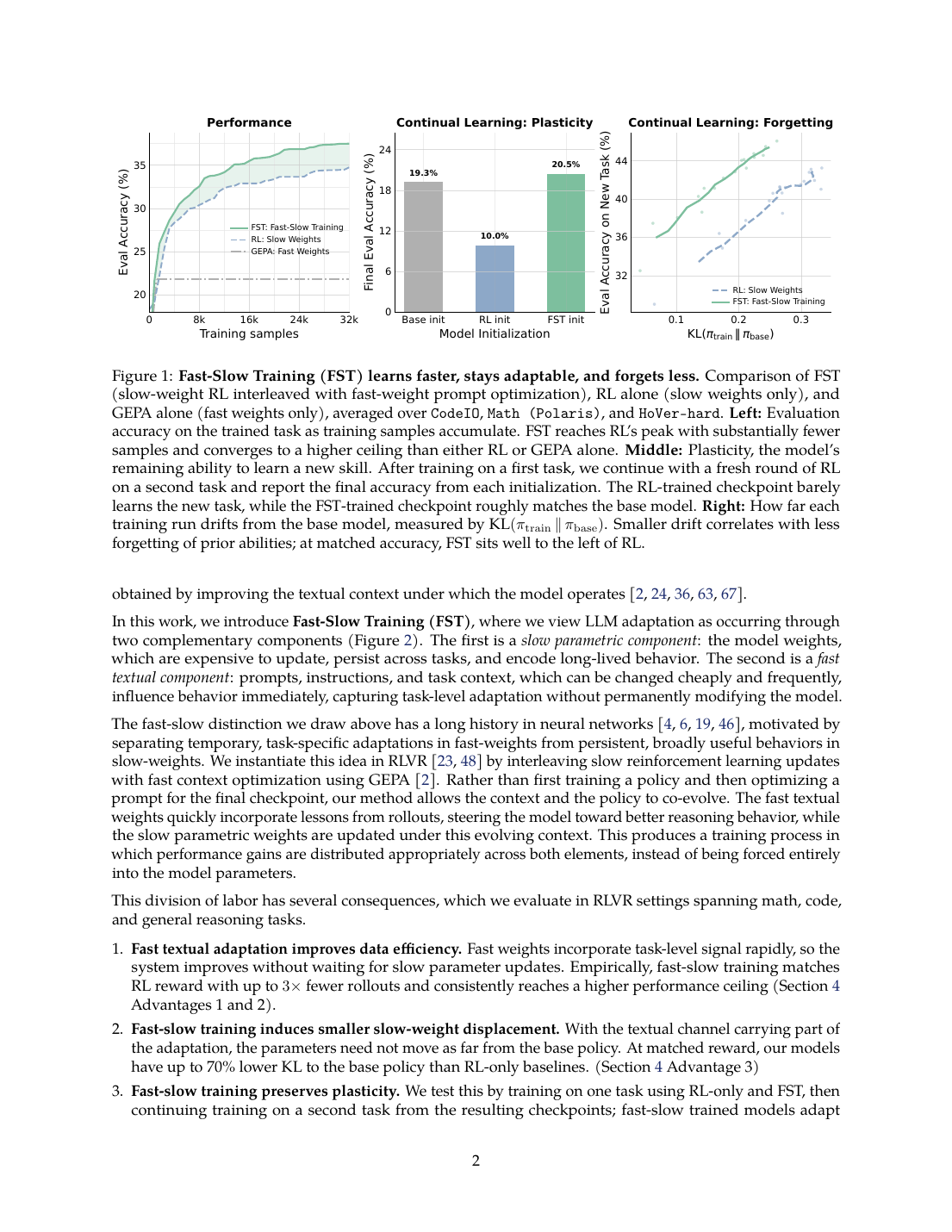
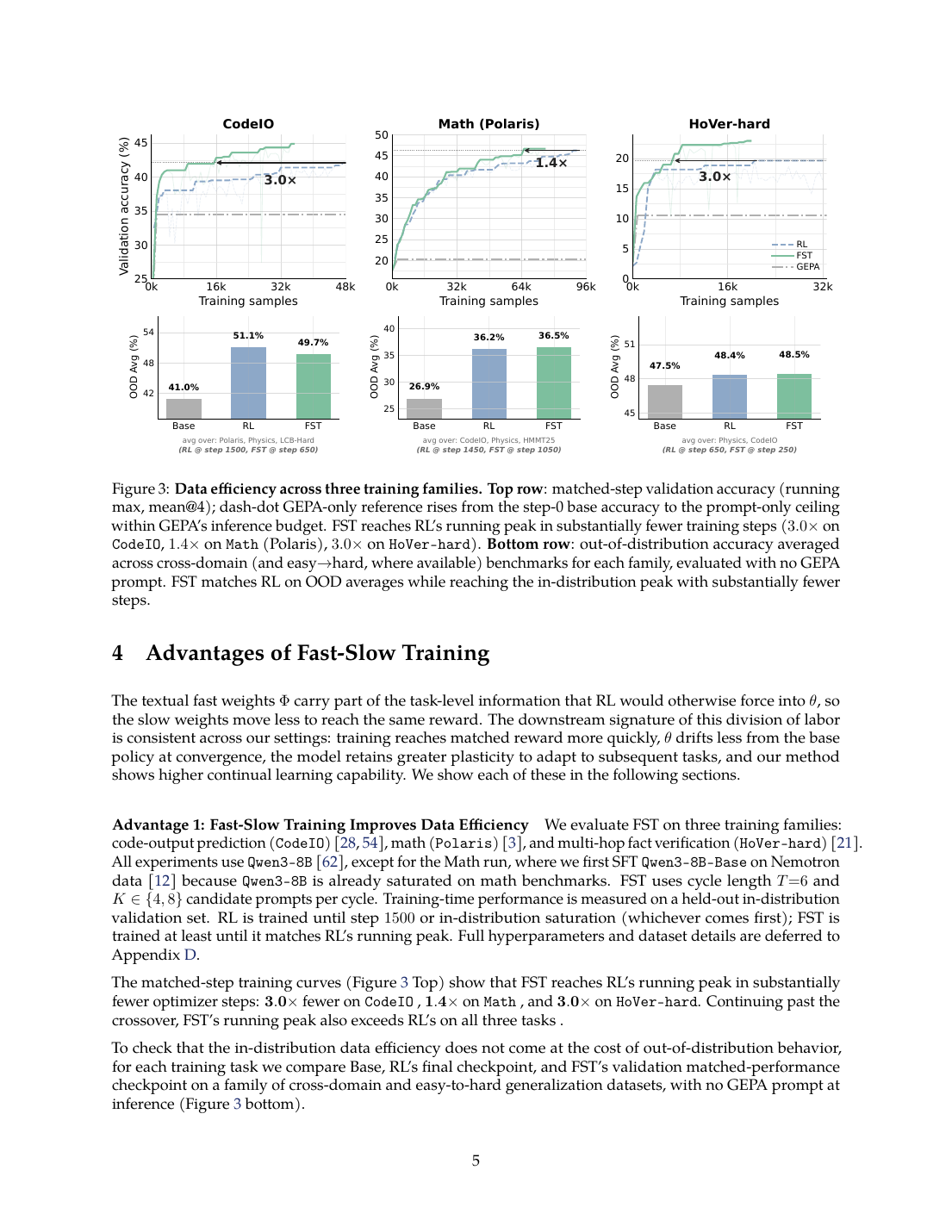
达到 RL running peak 所需训练样本更少:CodeIO 3.0x、Math 1.4x、HoVer-hard 3.0x。
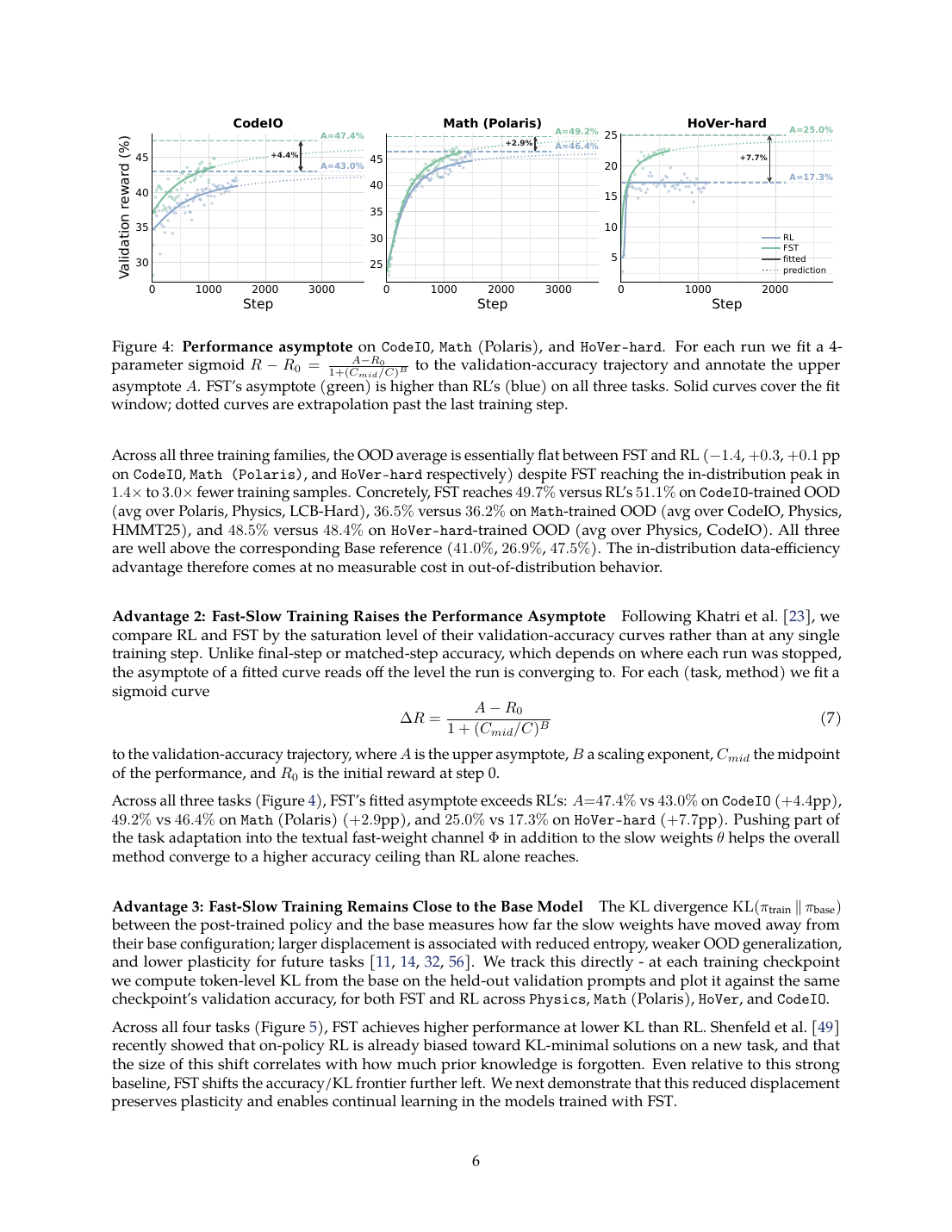
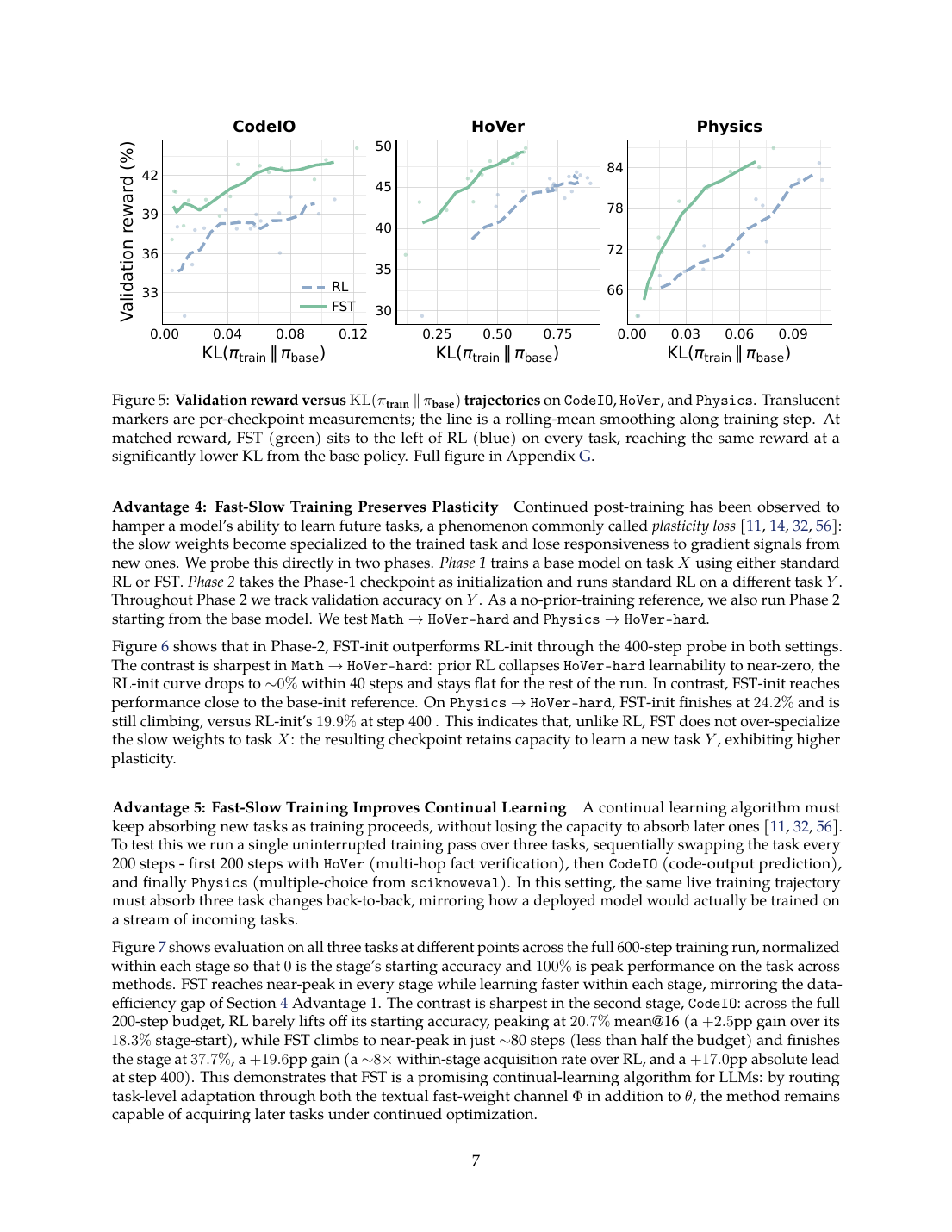
在相同 reward 附近,FST 的 slow weights 相对 base model 的 KL drift 更低。
Math -> HoVer-hard plasticity probe 中,RL-init 很快掉到近 0;FST-init 更接近 base-init。
原帖到底在说什么
线程不是在介绍一个普通 prompt tuning 技巧,而是在批评当前 RLVR pipeline 的顺序:先做 RL 后训练,把所有行为改进都压进权重;最后再做 prompt optimization。Raja 的观点是,这个顺序错了,prompt optimization 应该和 RL post-training 同步演化。
| 线程主张 | 翻译成技术问题 | 是否被论文支持 |
|---|---|---|
| RLVR 会把 durable skills、heuristics、recent rollout lessons 全塞进 slow weights。 | 模型参数同时承载长期能力、任务格式、临时纠错经验,容易导致 entropy collapse、KL drift、plasticity loss。 | 论文 introduction 和 KL/plasticity 实验直接围绕这个诊断展开。 |
| FST 的 fast channel 用 GEPA 维护 Pareto prompt population。 | 不是找一个单一最佳 prompt,而是保留多个互补 prompt,让不同 prompt 处理不同 problem slice。 | 论文算法明确维护 K 个 prompt,并在每个问题的 rollout group 内混合 prompt-induced variance。 |
| headline 不只是 3x sample efficiency,而是 plasticity。 | 训练完任务 X 后,模型是否还学得动任务 Y。 | Math -> HoVer-hard 和 Physics -> HoVer-hard 的二阶段实验支持这个点。 |
| RLVR pipeline 不应把 GEPA 放到最后。 | prompt tuning 不是后处理,而应成为训练时的 adaptation channel。 | 这是论文最核心的方法论主张,但在生产系统中还要看额外成本和复杂度。 |
论文要解决的问题
传统 RLVR 的基本形态是:给模型一个任务 prompt,让它生成多个答案,用 verifier 给 0/1 或分数 reward,然后通过 GRPO/PPO/CISPO 这类 policy-gradient 方法更新模型参数。这个流程对数学、代码、可验证问答很有效,但有一个结构性问题:所有改善都必须写进同一套权重。
这会造成三类混杂:
长期技能
例如更好的递归推理、代码执行心智模型、multi-hop retrieval 规划。这类知识值得进入权重。
任务格式
例如“输出 JSON”“最后一行放 boxed answer”“HoVer 要写检索 query”。这类更像 prompt-level protocol。
最近错误经验
例如刚才 rollout 失败是因为 off-by-one、漏读 parenthetical disambiguator、除零。这类经验短期有用,但不一定应永久写入参数。
FST 的核心洞见是:把这些信息全部压进参数,会让参数为了当前任务移动过多,表现为更高 KL drift、更低 entropy、对下一个任务更不敏感。相比之下,prompt / context 是廉价、可频繁更新、可按任务切换的“快权重”,很适合承载任务级和近期 rollout 级经验。
FST 方法一步一步讲
FST 不是替代 RL,也不是只做 prompt optimization。它把 RL 和 prompt optimization 交错起来:每隔几个 RL step,先用当前模型和近期 lookahead batch 进化 prompt;然后在新 prompt population 下继续更新模型权重。
初始化
有初始模型参数 theta_0 和 seed prompt phi_seed,prompt population 初始只有一个 prompt。
预取 lookahead batch
每个 cycle 开始时,预取接下来 T 个 RL minibatch,作为 GEPA 的 anchor/eval set。
GEPA 更新快权重
当前模型 rollout,reflection LM 阅读答案、错误、反馈,提出 prompt mutation,保留 Pareto frontier top-K。
混合 prompt 采样
每个问题采样 G=8 个 rollout,均匀分配给 K 个 prompt,形成同一个 group。
CISPO/GRPO 更新慢权重
按 per-problem group reward 计算 advantage,更新 theta;T=6 步后进入下一轮 GEPA。
慢通道:GRPO + CISPO 更新参数
对每个问题 x,模型生成一组答案 y_i,verifier 给每个答案 reward。group-relative advantage 的直觉是:同一道题内,比同组平均更好的答案得到正信号,比同组平均更差的答案得到负信号。这样可以减少不同题目难度差异带来的噪声。
快通道:GEPA 更新 prompt population
GEPA 的关键不是“随机搜索 prompt”,而是 reflective evolutionary prompt optimization:它把 rollout 的完整文本、错误、tool call、verifier feedback 交给一个冻结 reflection LM,让它用自然语言总结失败原因并改写 prompt。然后 GEPA 不只保留一个最好 prompt,而是保留 Pareto frontier,理由是不同 prompt 可能擅长不同题型。
这也是 FST 和“训练完再调 prompt”的差别:FST 的 prompt 在训练过程中不断变,模型权重是在这些不断演化的上下文条件下学习的。换句话说,模型学到的是“在一组更好的任务脚手架下如何行动”,而不是裸 prompt 下被迫把所有纠错经验写进权重。
实验到底评了什么
论文主实验覆盖三类训练任务,外加一个 Physics 任务用于 KL/plasticity 等分析。模型主要是 Qwen3-8B thinking 模式;Math 因为公开 Qwen3-8B 已经在数学上较饱和,所以作者用 Qwen3-8B-Base 在 Nemotron 上继续 SFT 得到一个 math base。
| 训练族 | 任务是什么 | 输出/评分对象 | 主要比较 |
|---|---|---|---|
| CodeIO | 代码输出预测 | 模型给出程序/输出,verifier 判断正确性;报告 validation accuracy / mean@4。 | RL-only vs FST vs GEPA-only;OOD 包括 Polaris、Physics、LCB-Hard。 |
| Math (Polaris) | 数学推理 | 最终答案是否正确;报告 validation accuracy / mean@4。 | RL-only vs FST;OOD 包括 CodeIO、Physics、HMMT25。 |
| HoVer-hard | 多跳事实验证 / 检索 query 构造 | 是否写出能检索到验证所需维基页面的 query;报告 validation accuracy。 | RL-only vs FST;OOD 包括 Physics、CodeIO。 |
| Physics | sciknoweval 多选物理题 | 选择 A/B/C/D;用于 KL curve 和 plasticity probe。 | 比较训练后权重 drift 与迁移到 HoVer-hard 的可学习性。 |
指标解释
| 指标 | 含义 | 为什么重要 |
|---|---|---|
| Validation accuracy / reward | 在 held-out validation prompts 上的正确率或 reward。 | 直接衡量训练任务上的效果。 |
| mean@4 | 每个 validation prompt 采样 4 次,取平均表现。 | 减少单次采样偶然性,适合 stochastic LLM。 |
| OOD average | 在非训练域任务上的平均表现。 | 检验 sample efficiency 是否靠过拟合当前任务换来。 |
| KL(pi_train || pi_base) | 训练后策略相对 base policy 的 token-level 分布距离。 | 越大表示权重行为漂移越远,通常和遗忘、低熵、plasticity loss 相关。 |
| Plasticity probe | 先在任务 X 训练,再从该 checkpoint 继续用 RL 学任务 Y。 | 评估模型是否还“学得动”新任务,而不只是当前任务分数高。 |
主结果
| 结论 | 数字 | 我如何解读 |
|---|---|---|
| 样本效率 | CodeIO 3.0x、Math 1.4x、HoVer-hard 3.0x 更少 optimizer steps 追上 RL peak。 | 这个结果说明 fast prompt channel 能快速吸收任务信号,尤其在 CodeIO/HoVer 这种格式和错误反馈强的任务上更明显。 |
| 性能上限 | 拟合 asymptote:CodeIO 47.4 vs 43.0,Math 49.2 vs 46.4,HoVer-hard 25.0 vs 17.3。 | FST 不只是快一点,还可能把 fast/slow 两类优化叠加出更高 ceiling;HoVer 的差距最大。 |
| KL drift | 在 matched reward 下,FST 曲线整体更靠左,摘要称最高可低 70%。 | 这支持线程里的“weights stay sane”:同样得分下,参数不必为了任务细节移动那么远。 |
| Plasticity | Math -> HoVer-hard:base-init 20.2%,RL-init 0.0%,FST-init 16.7%;Physics -> HoVer-hard:18.3/19.9/24.2%。 | 这是最有启发的实验:它直接测“训练之后还会不会学”,比单任务分数更贴近 continual learning。 |
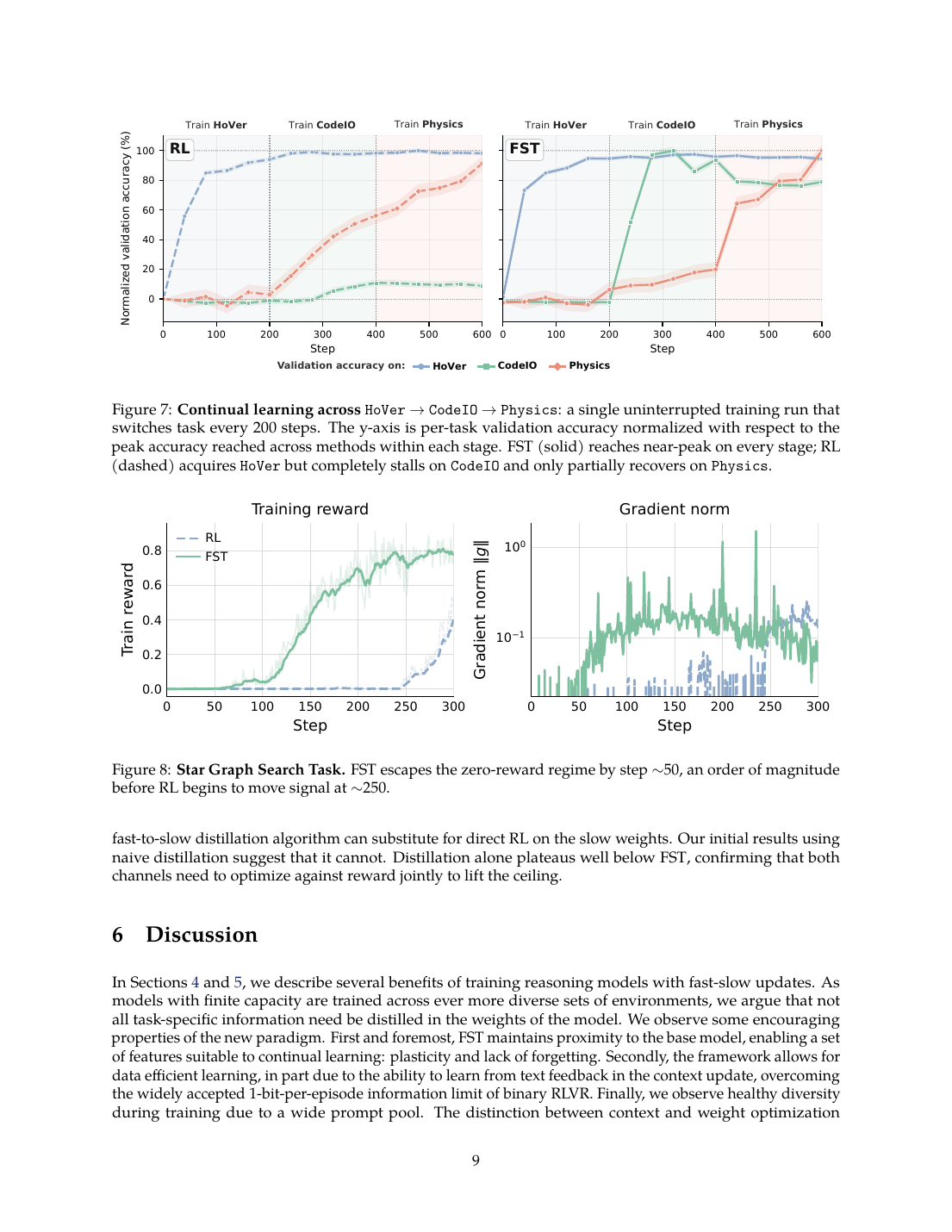
| Continual learning | HoVer -> CodeIO -> Physics 连续 600 step,每 200 step 换任务;FST 每阶段接近 peak,RL 在 CodeIO 阶段基本停滞。 | 证明 FST 的优势不仅是离线二阶段 probe,也能在任务流切换里体现。 |
边界和我会谨慎的地方
1. 训练总成本不是 headline 里的 3x
论文明确写了 FST 需要额外 GEPA cycles、reflection LM 和 prompt evaluation。若只看 RL optimizer steps,FST 更 sample-efficient;若看端到端 wall-clock、外部 LLM 调用费用、工程复杂度,结论要重新算。
2. Reflection LM 是强外部能力
GEPA 的 proposer 是 OpenAI gpt-5.2。也就是说,FST 的快通道借用了一个强模型来读错误、写 prompt。生产中若不能用同等强的 reflection LM,收益可能下降。
3. 任务类型偏 verifier-friendly
CodeIO、Math、HoVer、Physics 都能用较明确 reward 评分。开放式对话、安全、长程 agent 任务是否同样稳定,还没有被充分证明。
4. Code 目前未公开
arXiv 页面有 Code 链接,但我读取时作者 code 页面显示 “Code coming soon”。因此当前只能基于论文和 blog 复现实验设计,不能直接运行官方实现。
我的 Insight:这篇工作的真实价值
我认为这篇论文最重要的地方,不是提出了一个具体的 “GRPO + GEPA” recipe,而是把 post-training 里的“知识写入位置”问题讲清楚了。
现在很多 RLVR 讨论默认把所有 improvement 都看作应进入参数的东西:答错了,就用 reward 更新权重;格式错了,也更新权重;刚刚遇到某类 off-by-one,也更新权重。这在短期 benchmark 上看起来有效,但它会把“长期技能”和“短期工作记忆”混在同一个慢变量里。FST 的贡献是重新分配学习负载:长期、可泛化的 procedure 写进参数;任务格式、错误检查、近期反馈写进上下文。
这和人类学习直觉很像:你不会把每个项目的 checklist 都内化成永久神经回路。你会保留一部分为笔记、工具、规程、工作流。LLM 系统也应该如此。真正的 post-training pipeline 可能不再是单一 optimizer,而是一个多记忆层系统:weights、prompts、retrieval memory、tool state、eval feedback 都在不同时间尺度上更新。
如果我是要把这篇论文用到实际 RLVR pipeline,我不会马上照搬全量 FST,而会先做三个轻量实验:
| 实验 | 目的 | 通过标准 |
|---|---|---|
| 训练中 prompt refresh | 每 N 个 RL step 用失败样本生成/更新 task checklist prompt。 | 相同验证分数下 KL drift 下降,且 OOD 不掉。 |
| Prompt population 而非 single prompt | 比较单 prompt、top-K prompt、Pareto prompt 的 RL 训练效果。 | top-K 不只提高训练分数,还改善不同题型覆盖。 |
| Plasticity as first-class metric | 每个 RL recipe 都做 X -> Y 二阶段学习 probe。 | 不再只报告单任务 reward,而报告训练后是否还能学新任务。 |
因此我赞同 Raja 的重点:如果你已经在跑 RLVR,不应该把 GEPA/prompt optimization 当作最后的 inference-time polish。更合理的方向是把它作为训练时的 fast adaptation channel,让权重和上下文共同演化。但我会把这视为一个强研究方向,而不是已完全工程化的 recipe;缺少公开代码、依赖强 reflection LM、端到端成本仍需更透明的复现实验。
术语解释与概念边界
- Fast path
- 模型快速给出直觉式答案的能力,适合简单或熟悉问题,但容易在复杂任务中过早收敛。
- Slow path
- 通过更长推理、搜索或验证逐步修正答案的能力,成本更高但更适合难题。
- 训练时计算分配
- 训练不只决定答案格式,也决定模型何时应该多想、何时应该停止。
- 过度推理
- 慢思考不是总有益;简单题上过长推理可能引入错误、浪费 token 或破坏校准。
证据边界与资料索引
我读取并核对了三类材料:X 原线程、arXiv 论文和作者/GEPA 官方页面。X 线程短链解析到 arXiv;PDF 标题、作者、页数和版本已核验。
- X 线程:
https://x.com/RajaPatnaik/status/2055015053834006756,共 5 条,发布时间为 2026-05-14 19:59 UTC。 - 论文:Learning, Fast and Slow: Towards LLMs That Adapt Continually,arXiv:2605.12484v2,29 页。
- 作者链接:arXiv HTML 暴露了 Video / Blog / Code;Blog 可读,Code 页面当前显示 “Code coming soon”。
